- Bash. Leksykon kieszonkowy. Przewodnik dla użytkowników i administratorów systemów - Arnold Robbins
- Linux. Wiersz poleceń i skrypty powłoki. Biblia. Wydanie IV - Christine Bresnahan, Richard Blum
- Skrypty powłoki systemu Linux. Zagadnienia zaawansowane. Wydanie II - Mokhtar Ebrahim, Andrew Mallett
- Genialne skrypty powłoki. Ponad 100 rozwiązań dla systemów Linux, macOS i Unix - Dave Taylor, Brandon Perry
- Linux. Podręcznik dewelopera. Rzeczowy przewodnik po wierszu poleceń i innych narzędziach - David Cohen, Christian Sturm
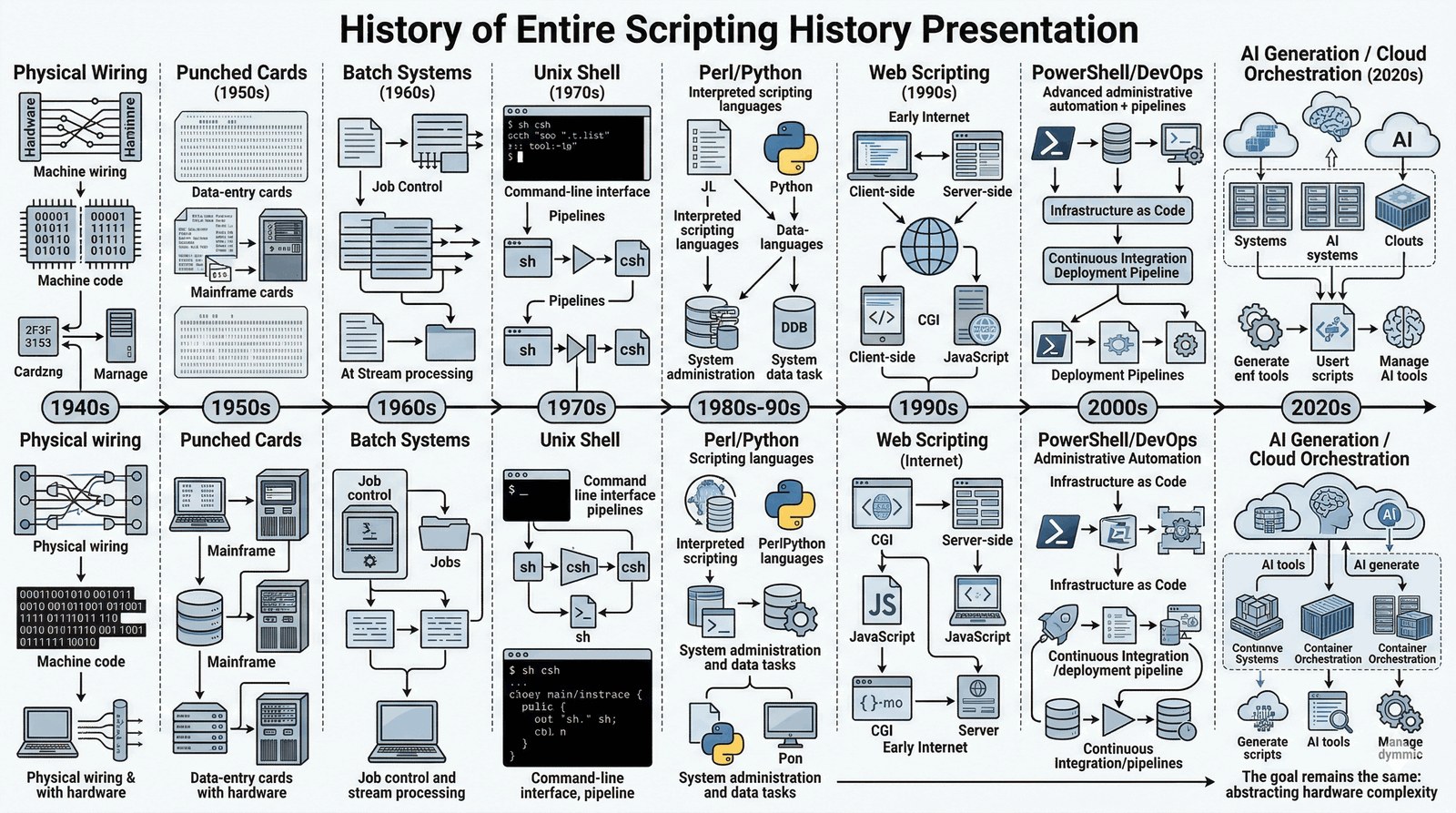
Od operatorów do inteligentnych algorytmów
Historia języków skryptowych to fascynująca podróż od fizycznego przełączania kabli do abstrakcyjnych warstw kodu, które zarządzają dzisiejszą infrastrukturą chmurową. Dla studenta IT zrozumienie tej ewolucji jest kluczowe, aby pojąć różnicę między programowaniem systemowym a zintegrowaną automatyzacją.
- Automatyzacja jako paradygmat: Skryptowanie narodziło się z potrzeby oszczędności czasu i eliminacji błędów ludzkich.
- Abstrakcja: Ewolucja od sterowania sprzętem do sterowania oprogramowaniem.
- Produktywność: Skrypty pozwalają na szybkie rozwiązywanie problemów bez konieczności przechodzenia przez długi cykl kompilacji.
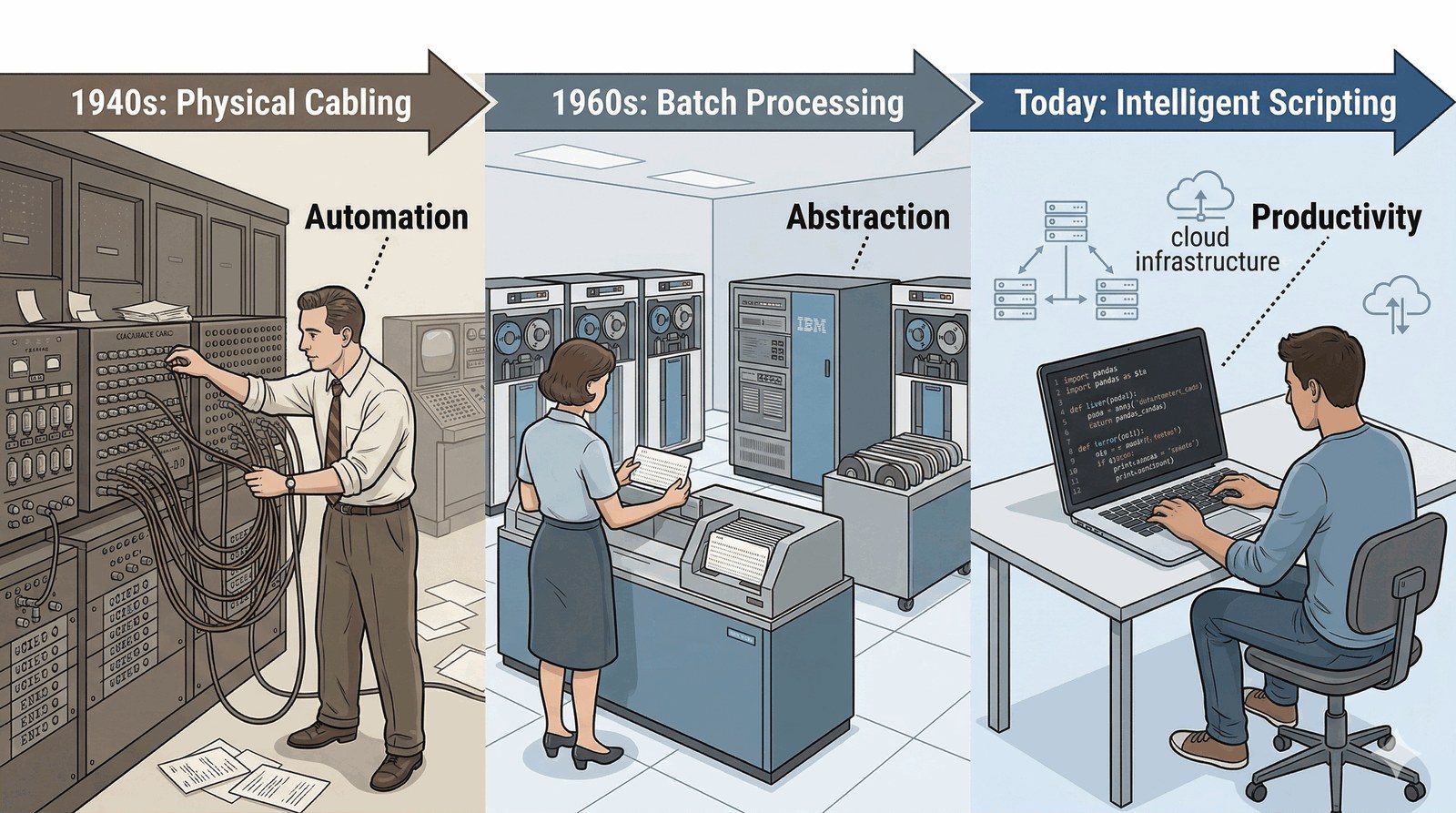
W tej prezentacji przyjrzymy się, jak przetwarzanie wsadowe ukształtowało nowoczesne systemy operacyjne.
[ Manual Work ] -> [ Batch ] -> [ Scripting ]
Lata 40. Lata 60. Dzisiaj
Skrypt vs język programowania
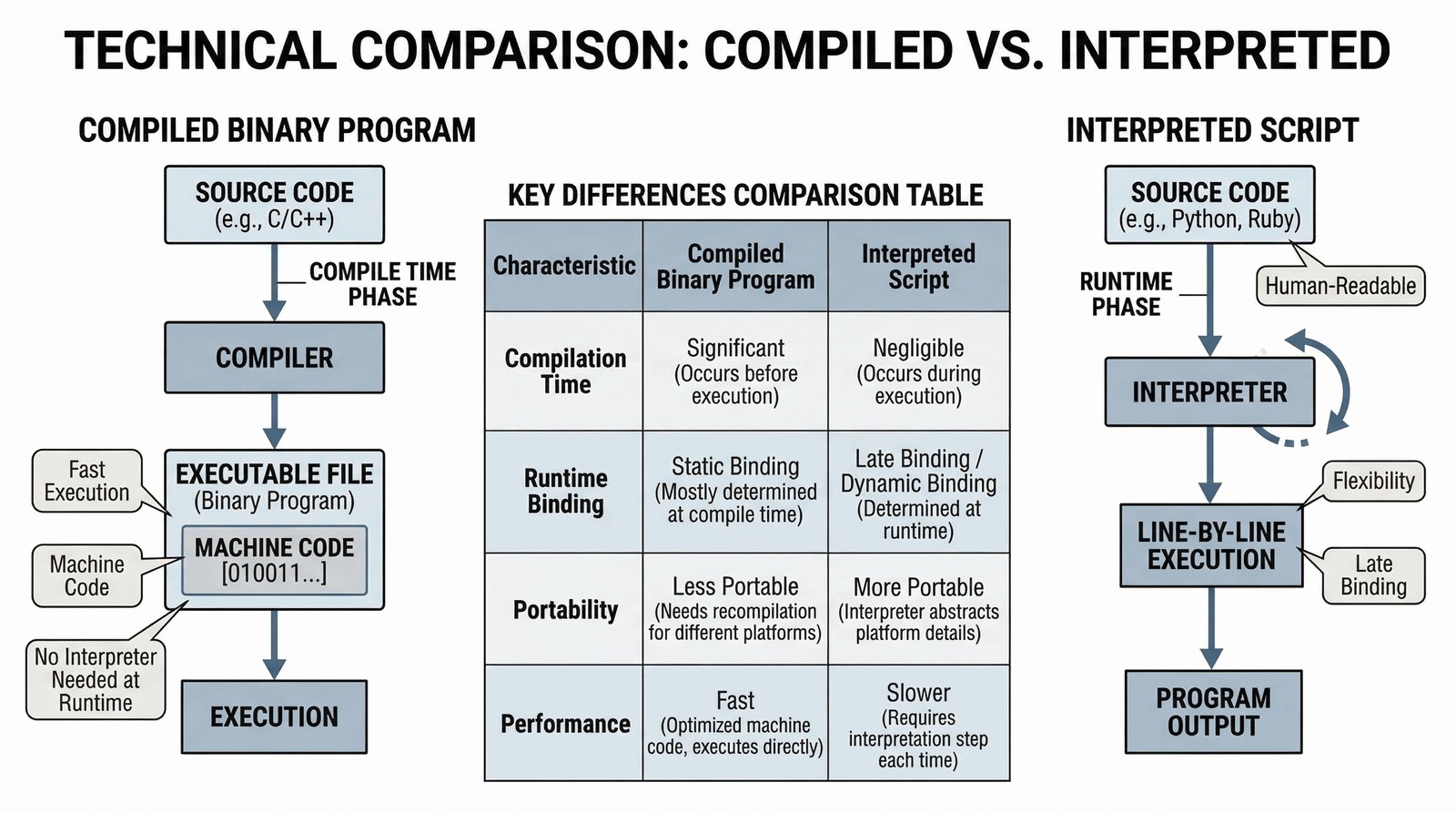
Z technicznego punktu widzenia granica między skryptem a programem binarnym często się zaciera, jednak dla celów edukacyjnych przyjmujemy kilka kluczowych różnic:
- Interpretacja: Skrypty zazwyczaj nie są kompilowane do kodu maszynowego przed uruchomieniem. Są czytane i wykonywane przez inny program - interpreter.
- Późne wiązanie: Typy danych i odwołania do bibliotek są często rozstrzygane w czasie wykonywania kodu (runtime), co daje ogromną elastyczność kosztem wydajności czysto obliczeniowej.
- Spajanie (Glue Logic): Skryptowanie służy przede wszystkim do sklejania (orkiestracji) gotowych modułów napisanych w językach niskopoziomowych (jak C lub C++).
Dziś skrypty (np. Python) są podstawą data science i DevOps właśnie dzięki tej elastyczności.
[Binary Program] [Script]
| Kompilacja | | Interpretacja |
| Szybkość | vs | Elastyczność |
| Maszyna | | Człowiek |
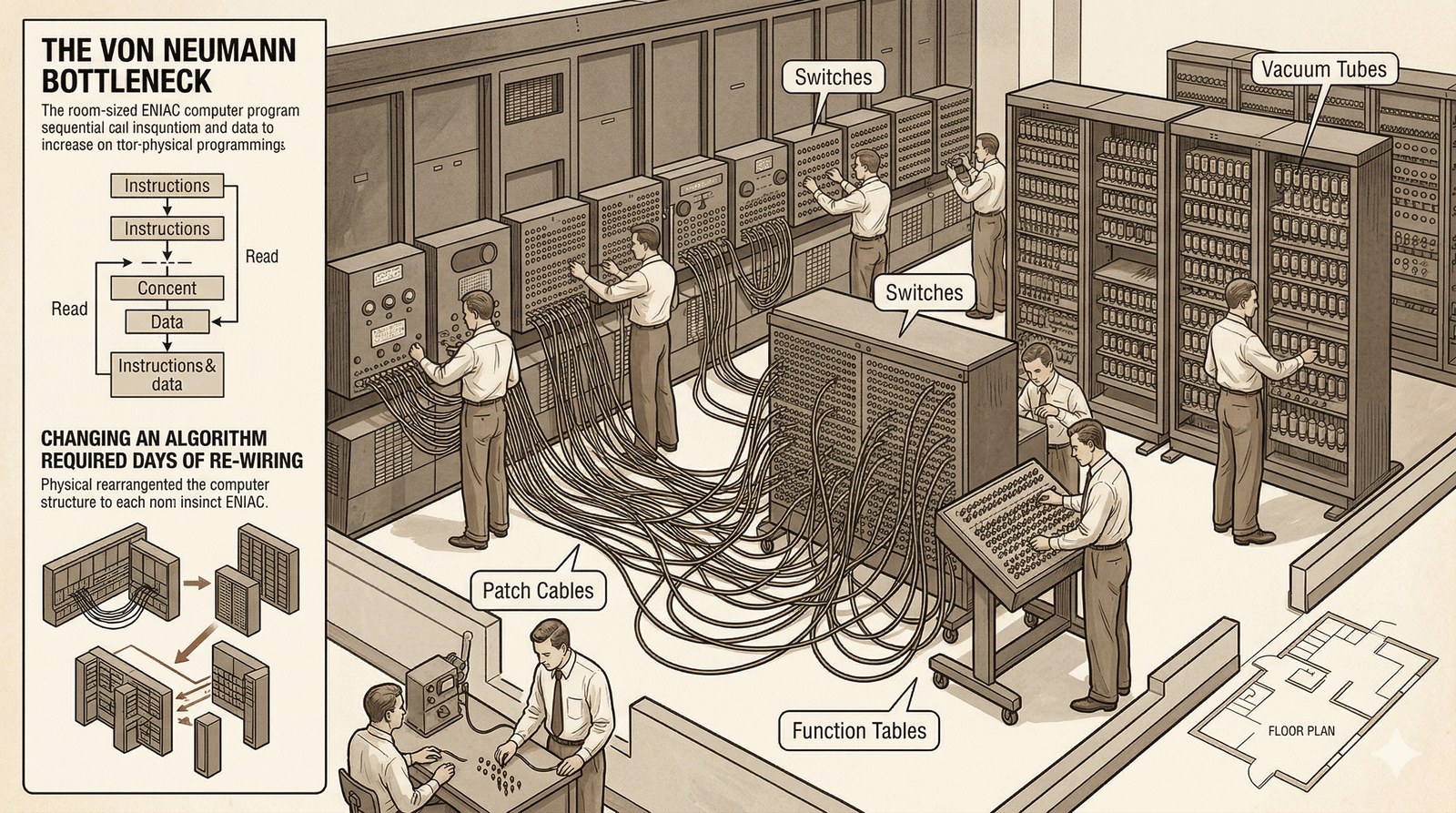
Programowanie przez okablowanie
W czasach ENIAC-a nie istniały pojęcia takie jak "bash" czy "python". Programowanie było zadaniem fizycznym.
- Kable połączeniowe: Ustawienie komputera do wykonania zadania polegało na ręcznym przełączaniu setek kabli i ustawianiu tysięcy przełączników na panelach.
- Von Neumann Bottleneck: Idea separacji procesora od pamięci dopiero się rodziła. Instrukcje nie były przechowywane w pamięci jako dane (do czasu EDVAC).
- Utrzymanie: Zmiana algorytmu mogła zająć kilka dni ciężkiej pracy zespołu inżynierów.
To tutaj narodziło się marzenie o sposobie, który pozwoliłby sterować maszyną za pomocą prostych poleceń tekstowych.
HAND-WIRING THE ALGORITHM
(No software layer yet)
[PUMP] <---> [CABLE] <---> [GATE]
Operator jako pętla sterująca
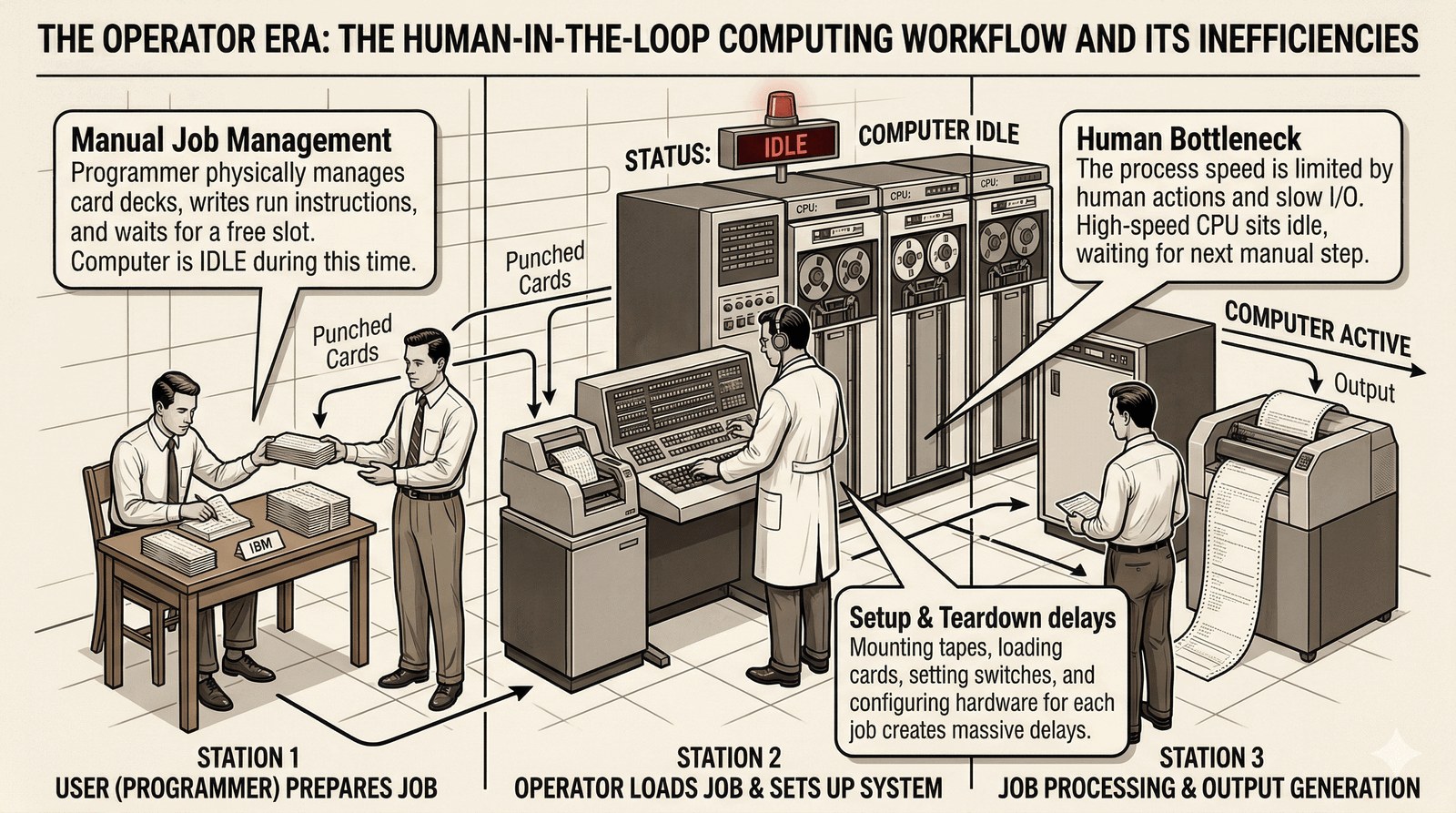
Gdy komputery zaczęły czytać programy z kart, człowiek wciąż był kluczowym elementem "systemu operacyjnego".
- Ręczne zarządzanie zadaniami: Programista (użytkownik) nie miał bezpośredniego dostępu do maszyny. Oddawał talie kart operatorowi.
- Przygotowanie i zakończenie: To operator decydował, kiedy załadować dany kompilator, jaką taśmę magnetyczną zamontować i kiedy wyczyścić rejestry procesora.
- Nieefektywność: Maszyna stała bezczynnie przez długie minuty, podczas gdy człowiek zmieniał papier w drukarce lub ładował nową talię kart.
Pierwsze systemy operacyjne powstały właśnie po to, by wyeliminować to "ludzkie wąskie gardło".
USER -> PUNCH CARDS -> [OPERATOR]
|
V
COMPUTERS
Instrukcje zapisane w dziurkach
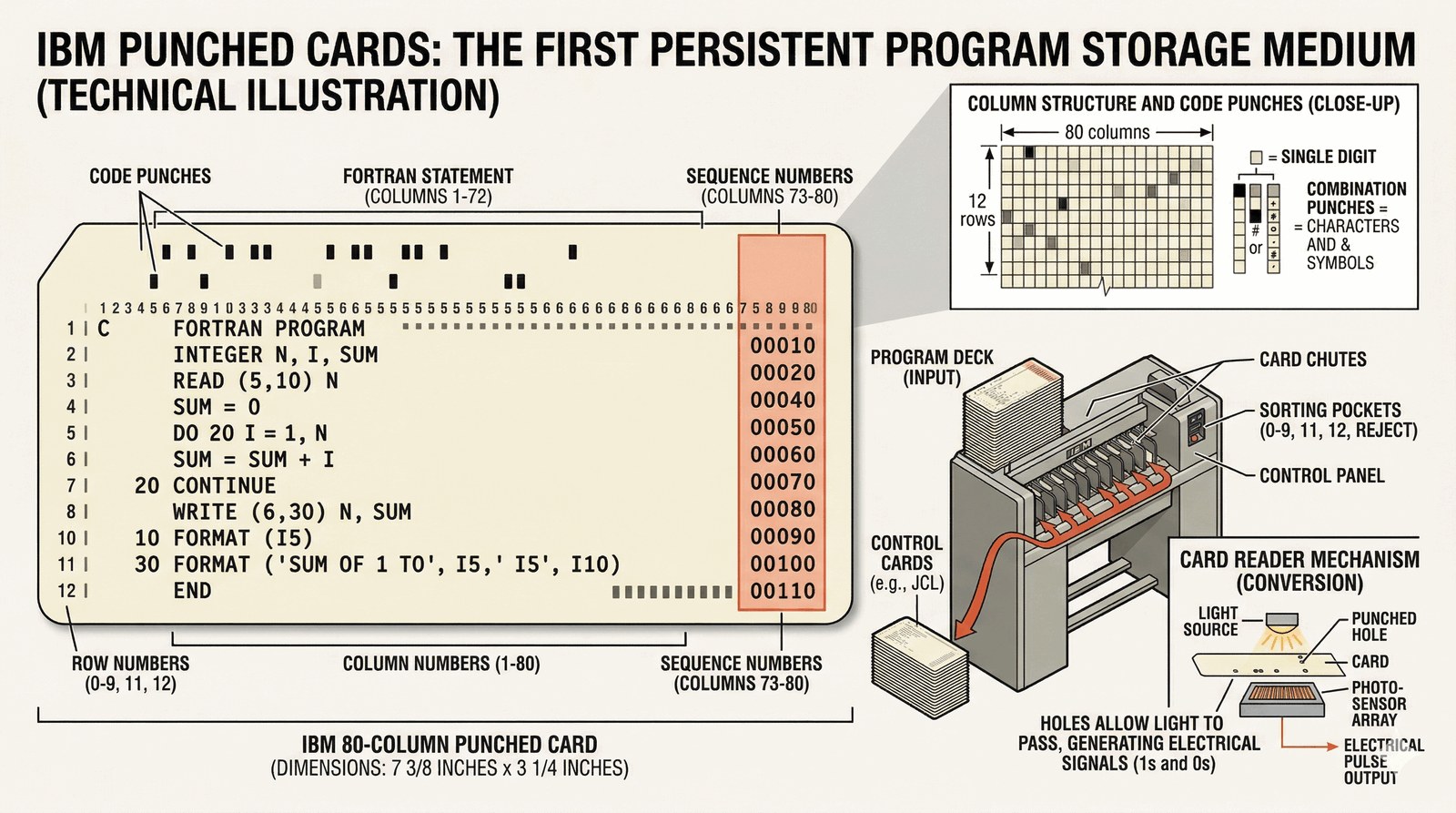
Karta perforowana była pierwszym trwałym nośnikiem, który pozwolił oddzielić tworzenie kodu od jego wykonywania.
- Format 80 kolumn: Klasyczna karta IBM miała 80 kolumn. Kolumny 73-80 były często rezerwowane na numery sekwencyjne (jeśli talia spadła na ziemię, można było ją odtworzyć!).
- Programy jako obiekty: Talia kart stała się fizyczną reprezentacją programu.
- Karty kontrolne: Oprócz kart z kodem (np. w Fortranie), zaczęto stosować specjalne karty sterujące, które mówiły czytnikowi: "to jest zadanie A", "użyj tego kompilatora".
Te karty sterujące były de facto pierwowzorem pierwszych linii poleceń i skryptów.
[ ] [ ] [ ] [x] [ ] [ ]
[ ] [x] [ ] [ ] [ ] [x]
[ ] [ ] [ ] [ ] [x] [ ]
KARTA TO LINIJKA KODU
Początek automatyzacji zadań
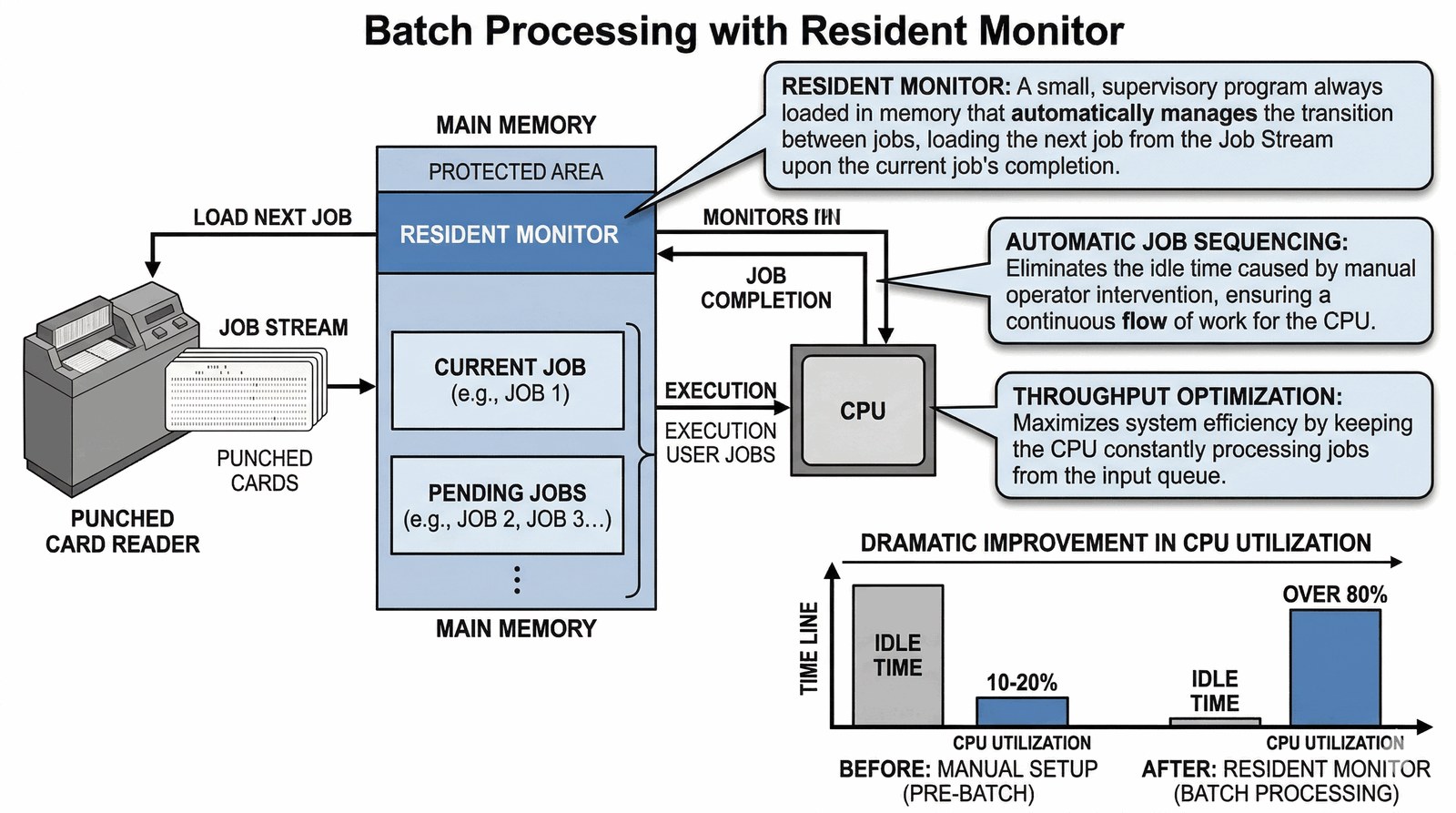
W systemach wsadowych zadania są grupowane w sekwencje wykonywane bez przerwy.
- Resident Monitor: Pierwsza forma systemu operacyjnego. Program, który stale rezydował w pamięci i automatycznie ładował kolejne zadanie (job) z czytnika kart.
- Job Stream: Ciągły strumień danych i instrukcji trafiający do procesora.
- Optymalizacja: Dzięki eliminacji ręcznego ładowania programów, wykorzystanie procesora wzrosło z 10-20% do ponad 80%.
To tutaj narodziła się idea przetwarzania wsadowego, która do dziś króluje w obróbce dużych zbiorów danych.
REZYDENTNY MONITOR:
1. Read JCL Card
2. Load Compiler
3. Run Program
4. Repeat...
Przepustowość ponad responsywność
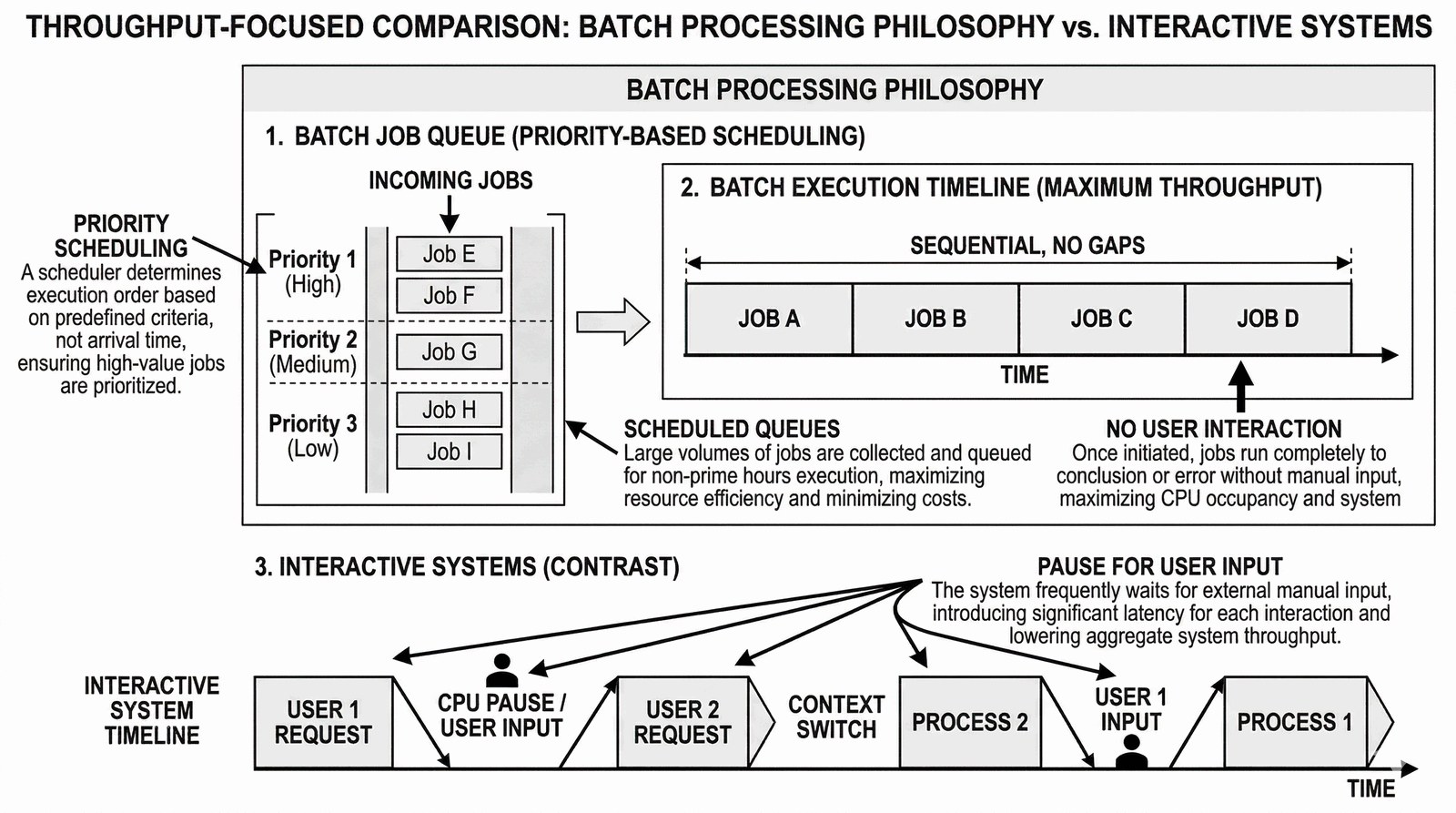
Dla studenta IT ważne jest rozróżnienie dwóch podejść: systemów interaktywnych i wsadowych.
- Brak interakcji: Jeśli system wsadowy napotka błąd, nie pyta użytkownika co zrobić - przerywa zadanie, zrzuca pamięć i przechodzi do następnego.
- Planowanie: Wprowadzono pojęcie kolejek zadań o różnych priorytetach.
- Wydajność: Głównym celem była maksymalna przepustowość maszyny, czyli liczba zadań wykonanych w jednostce czasu.
Współczesne skrypty często działają w tym trybie (np. nocne kopie zapasowe).
THROUGHPUT (Wydajność)
^
| [ JOB A ]
| [ JOB B ]
| [ JOB C ]
+-------------->
CZAS
Język instrukcji dla mainframe
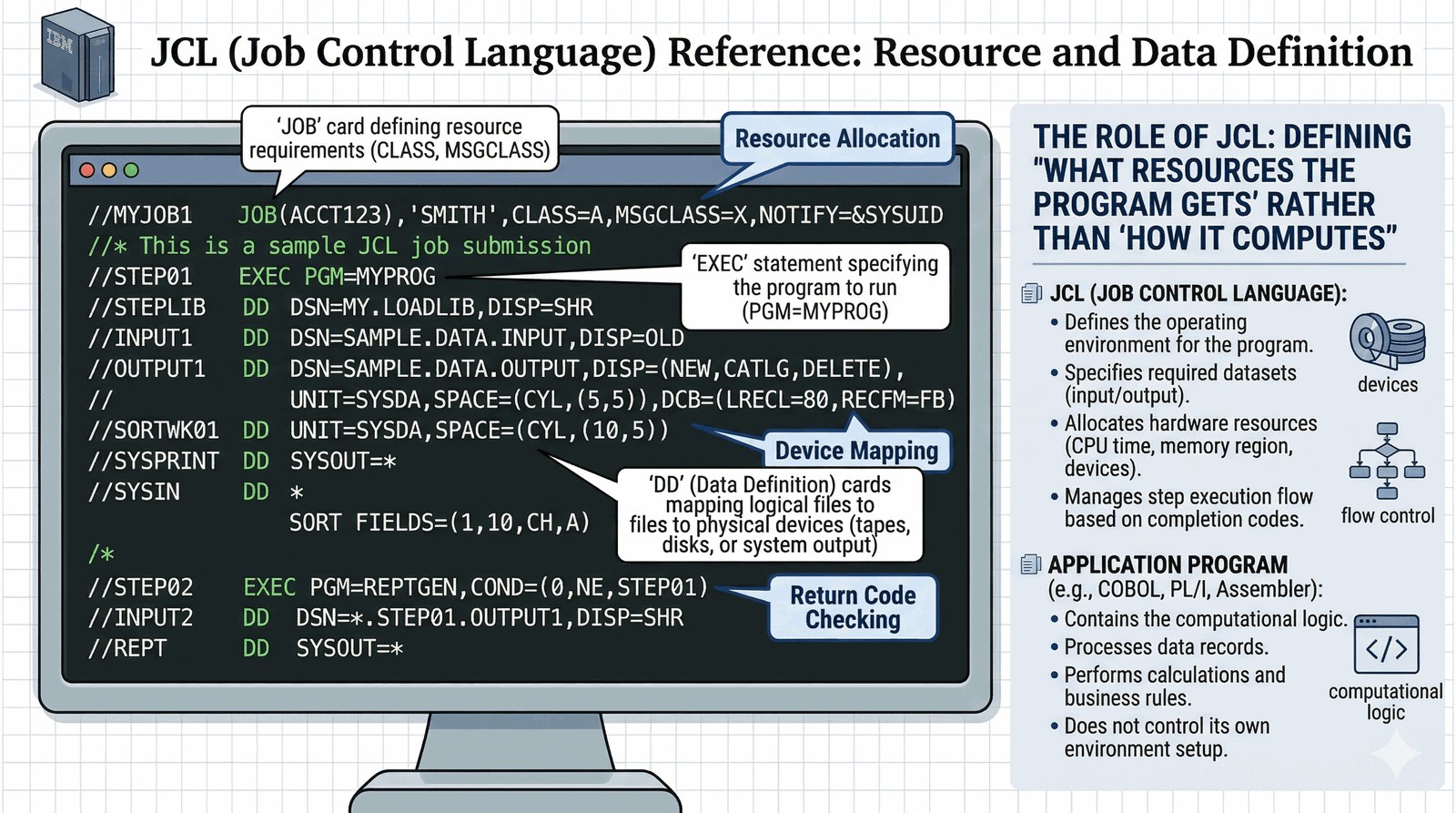
JCL (Job Control Language) to weteran skryptowania używany w systemach IBM (z/OS). Mimo upływu lat, jego koncepcje są wciąż żywe.
- Definiowanie zasobów: JCL nie mówi "jak program ma liczyć", ale "co program ma do dyspozycji".
- Karty DD: Służyły do mapowania logicznych nazw plików w programie na fizyczne urządzenia (dyski, taśmy).
- Warunkowość: Pozwalała na proste sprawdzenie kodu wyjścia poprzedniego kroku i podjęcie decyzji czy kontynuować.
JCL to dowód na to, że skryptowanie to przede wszystkim zarządzanie zasobami.
//PRACA1 JOB CLASS=A
//KROK1 EXEC PGM=ANALIZA
//DANE DD DSN=MOJE.PLIKI
//LOG DD SYSOUT=A
Powrót człowieka do terminala
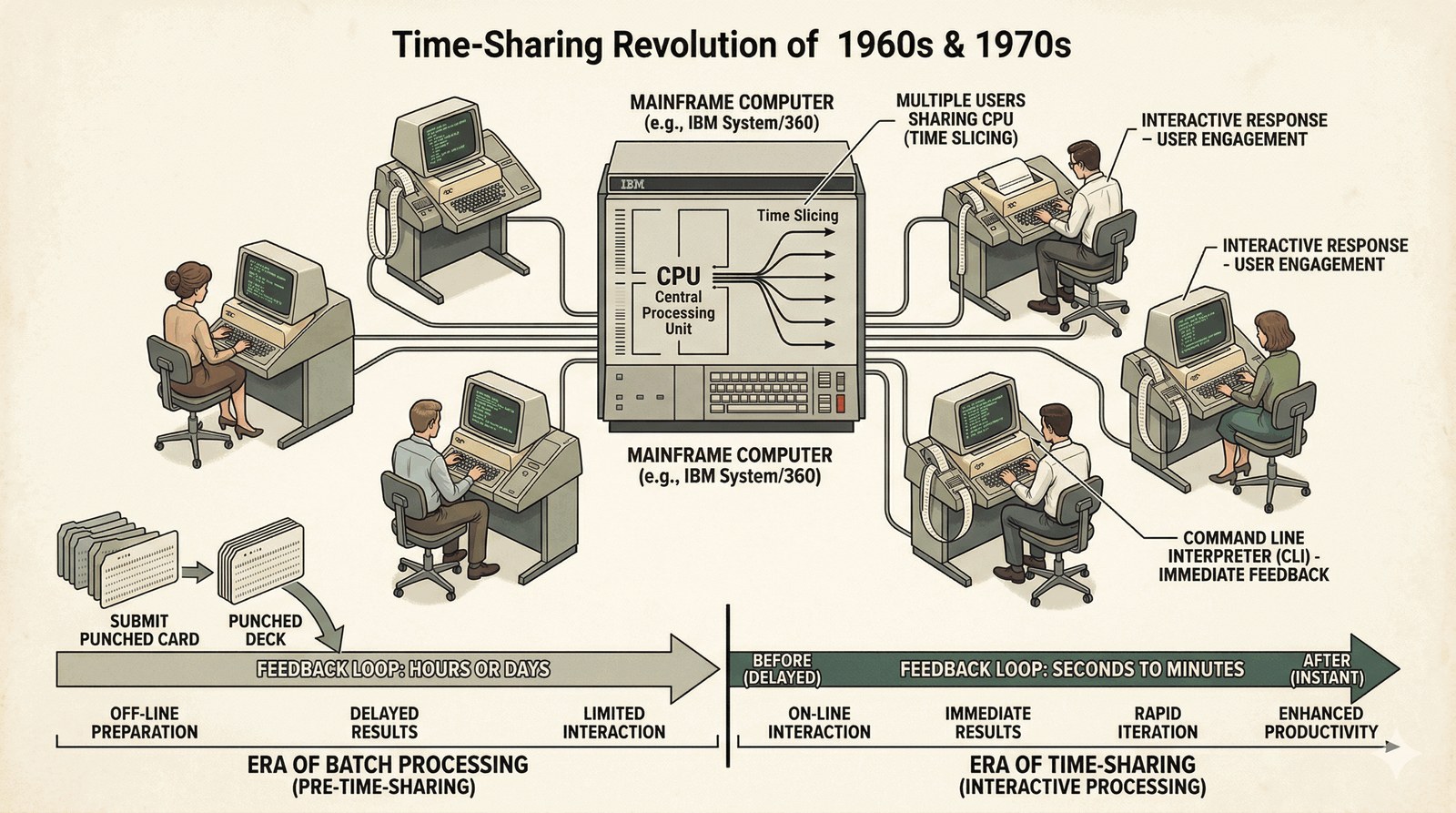
Przełomem było wprowadzenie współdzielenia czasu procesora, co pozwoliło wielu osobom pracować jednocześnie na jednej maszynie.
- Interaktywność: Programista mógł wpisać komendę i dostać wynik w sekundę. To wymusiło powstanie inteligentniejszych interpreterów linii poleceń.
- Psychologia: Skrócenie pętli zwrotnej drastycznie zwiększyło tempo innowacji.
- Ewolucja Shell: Pojawiły się pierwsze systemy (jak CTSS czy Multics), które traktowały powłokę jako osobny program, a nie część jądra.
Bez interaktywności nie byłoby nowoczesnego skryptowania.
[USER 1] --\
[USER 2] ---> [ CPU ]
[USER 3] --/ (Szeroki dostęp)
Filozofia Uniksa
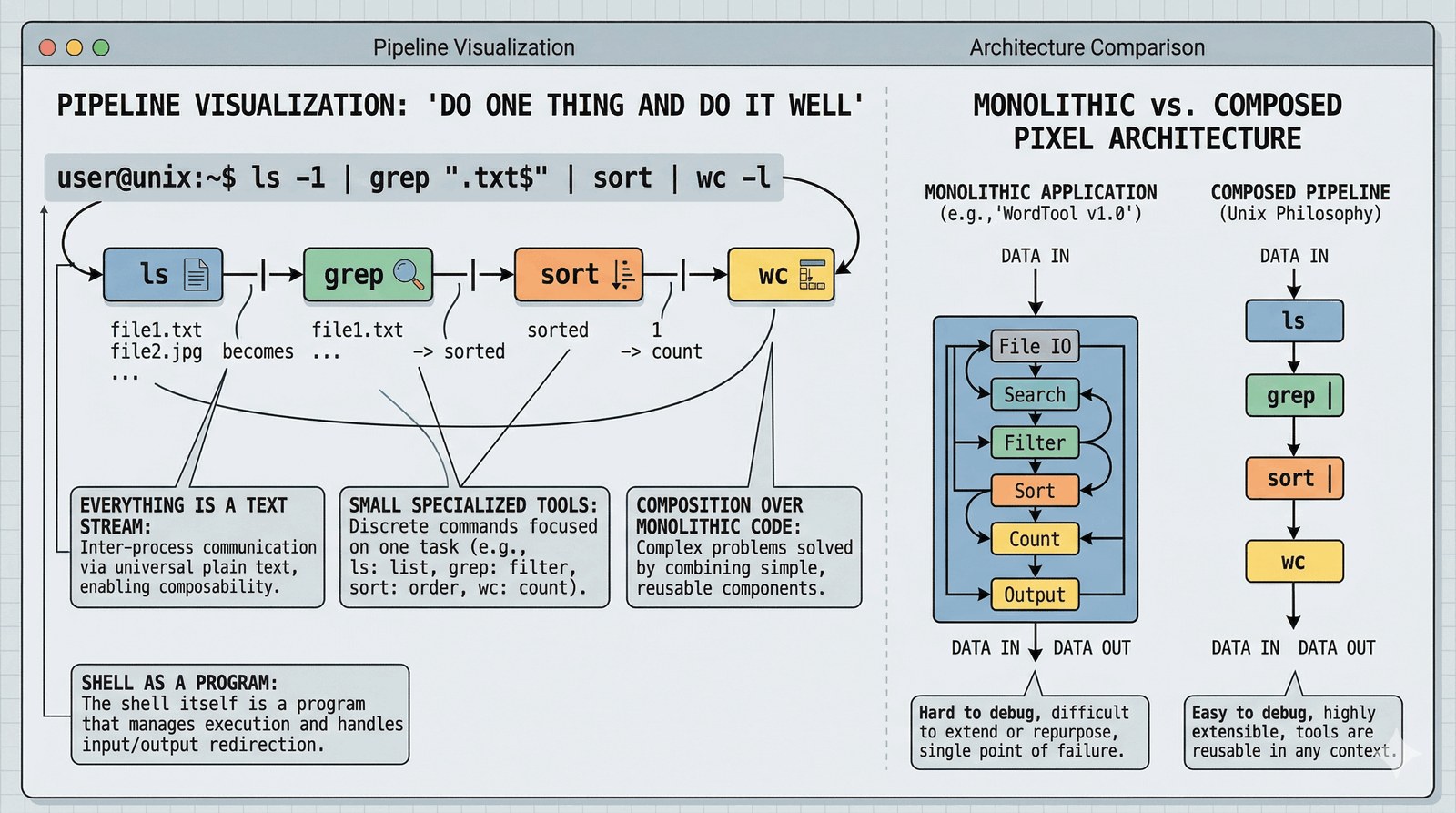
W 1969/1970 roku w Bell Labs narodził się Unix, a wraz z nim zasady, które rządzą dzisiejszym światem IT.
- Write programs that do one thing and do it well: Małe, wyspecjalizowane narzędzia są łatwiejsze do automatyzacji.
- Wszystko jest strumieniem tekstu: Dane przesyłane między skryptami to prosty tekst UTF-8/ASCII, co eliminuje skomplikowane problemy kompatybilności binarnej.
- Composition: Moc systemu nie tkwi w jednym wielkim programie, ale w możliwości łączenia małych części w potężne skrypty.
Dla Uniksa "shell" to tylko kolejny program, który można dowolnie wymieniać.
[ Tool A ] --> [ Tool B ]
^ |
|____( PIPE )__|
Interfejs jako program
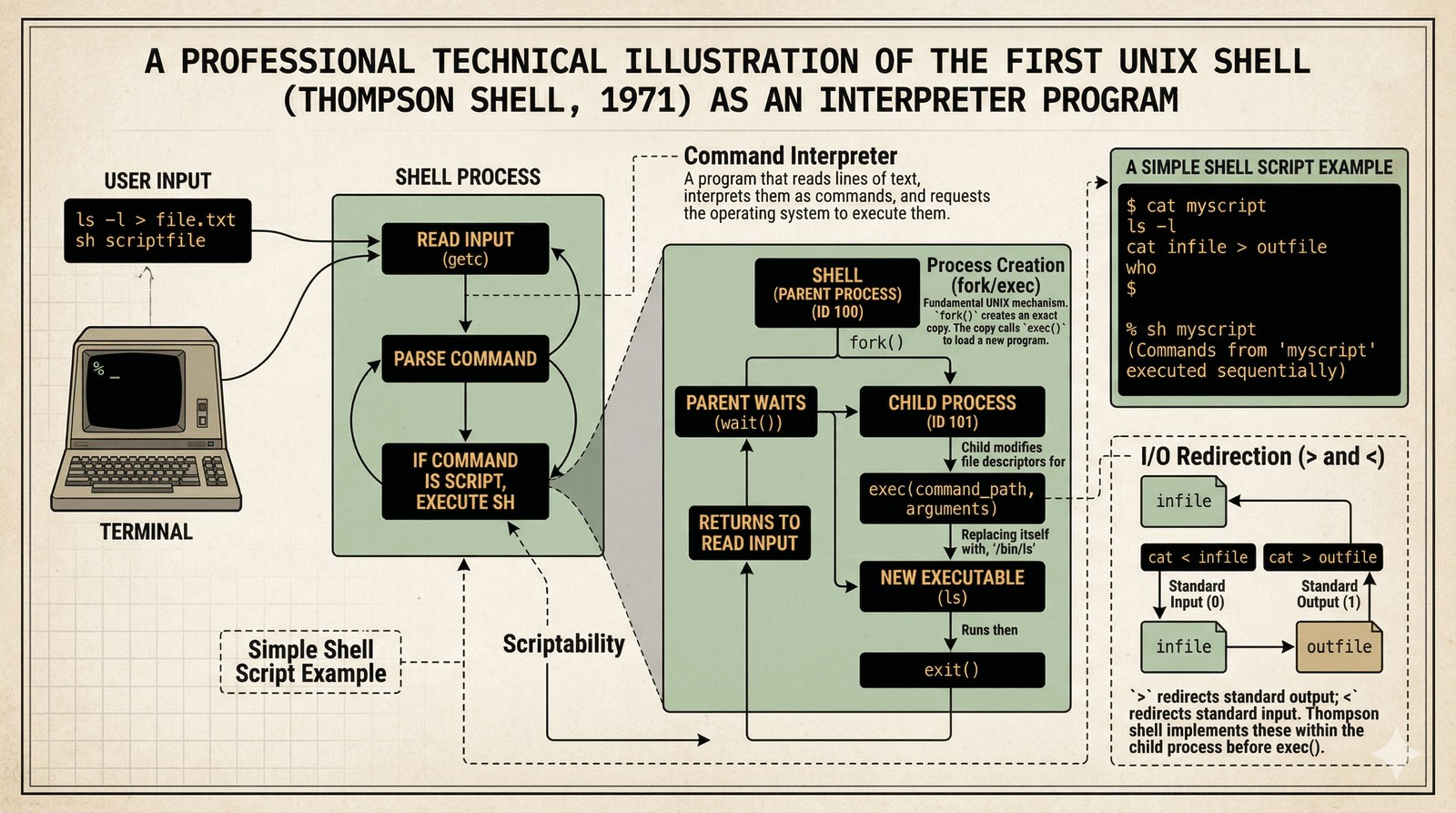
W 1971 roku Ken Thompson stworzył pierwszą powłokę (Thompson Shell). Dla studenta IT najważniejszym wnioskiem jest to, że shell to zwykły program, a nie integralna część jądra.
- Interpreter poleceń: Czyta polecenia użytkownika, znajduje odpowiednie pliki binarne na dysku i tworzy dla nich nowe procesy (fork/exec).
- Abstrakcja wejścia/wyjścia: Wprowadził proste przekierowania (
>,<), co pozwoliło zapisywać wyniki pracy programów do plików bez modyfikacji ich kodu. - Scriptability: Możliwość zapisania serii komend w pliku tekstowym sprawiła, że interfejs stał się "programowalny".
$ cat script.sh
ls -l
whoami
$ sh script.sh
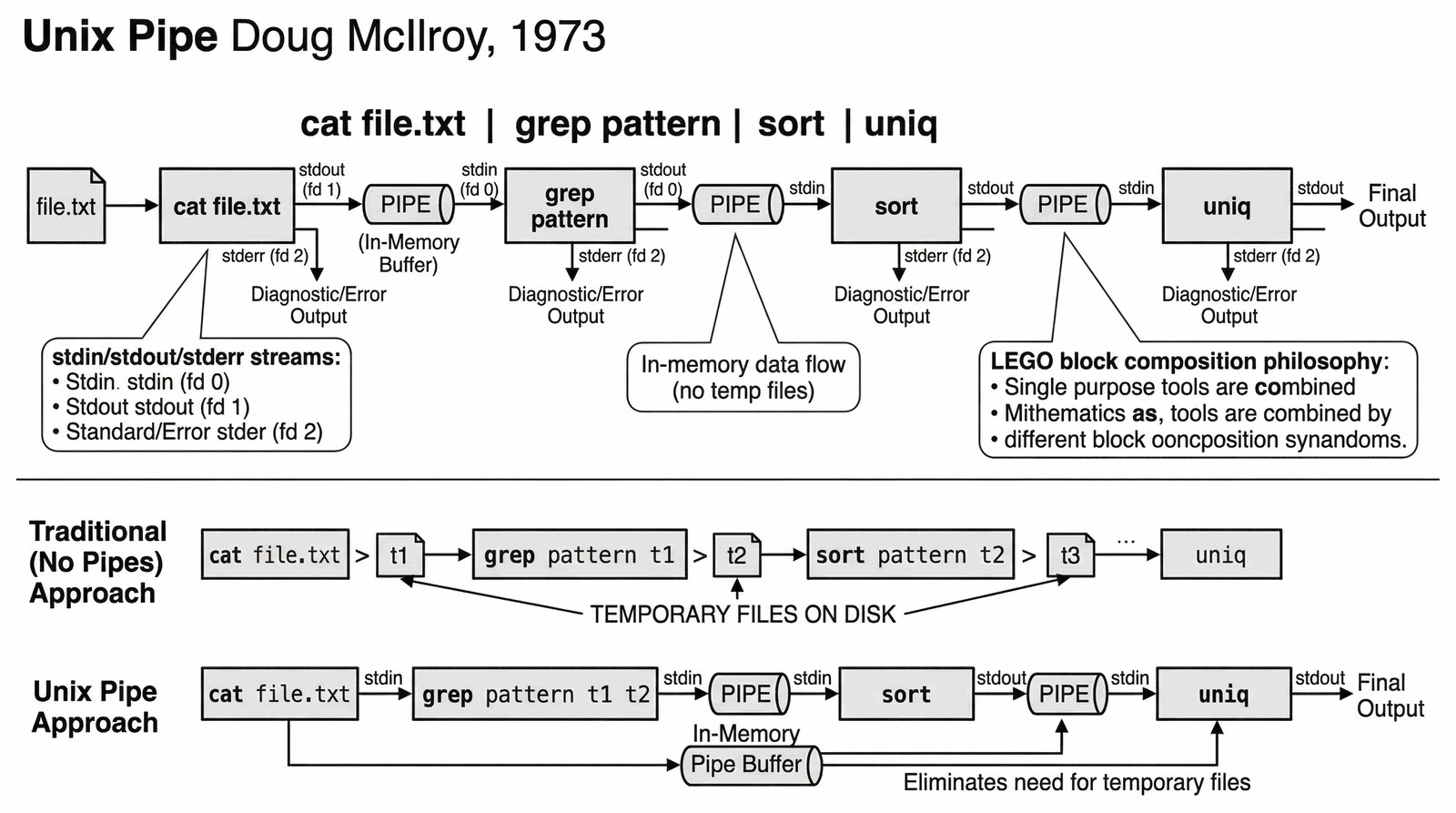
Łączenie strumieni danych
W 1973 roku Doug McIlroy zaproponował koncepcję potoku (pipe), która do dziś jest fundamentem skryptowania systemowego.
- Standardowe strumienie: Każdy program ma
stdin(wejście),stdout(wyjście) istderr(błędy). - Pipe (|): Pozwala połączyć stdout jednego programu z stdin drugiego bezpośrednio w pamięci RAM, bez użycia plików tymczasowych.
- Filozofia klocków LEGO: Możesz zbudować dowolnie skomplikowane narzędzie, łącząc proste programy (np.
cat | grep | sort | uniq).
To podejście drastycznie redukuje potrzebę pisania dużych, monolitycznych aplikacji.
ls | grep "\.txt" | wc -l
(Bez plików tymczasowych!)
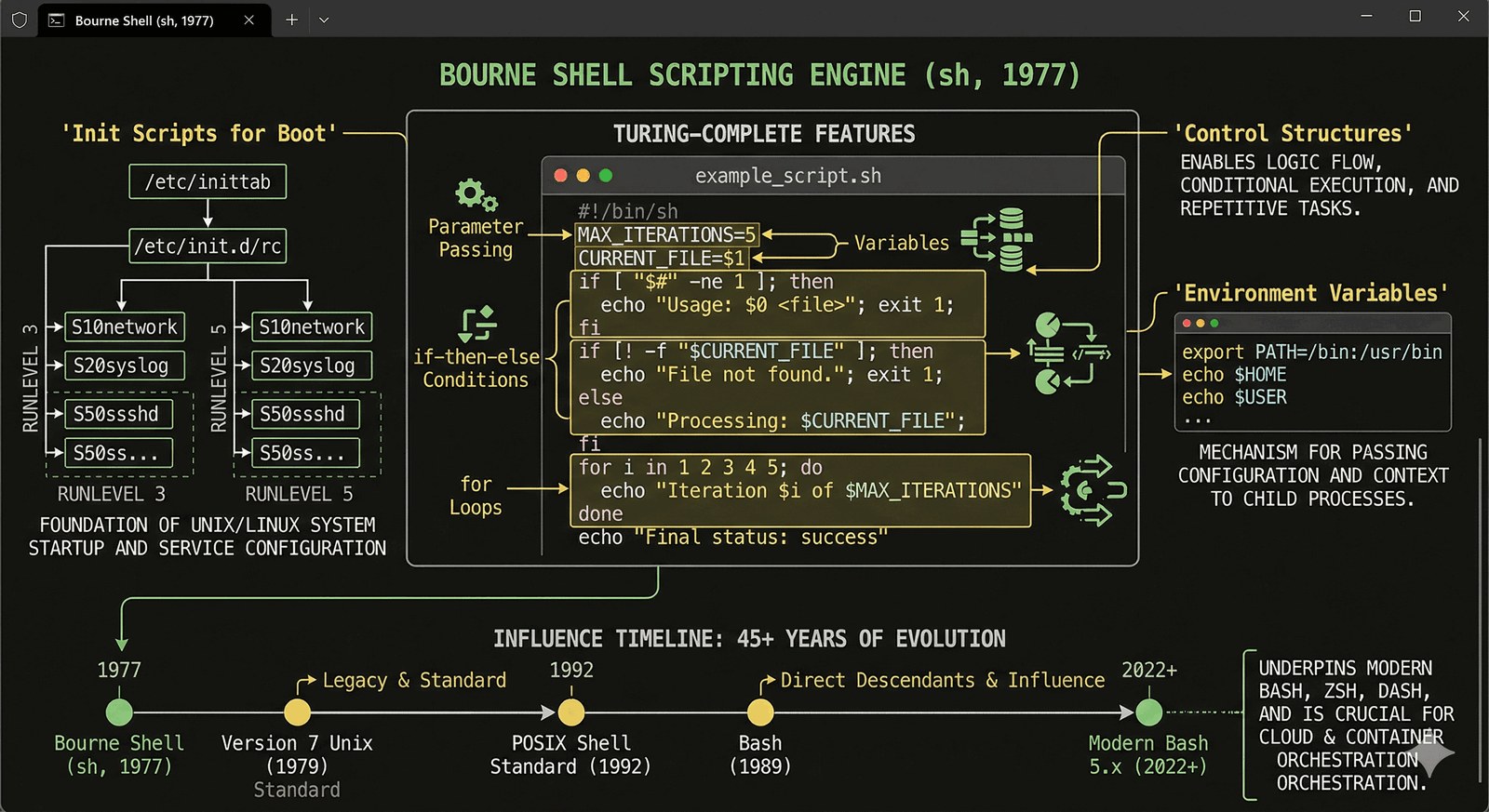
Pierwszy prawdziwy język skryptowy
Stephen Bourne stworzył powłokę sh, która stała się standardem w systemie Unix Version 7 i zdefiniowała składnię skryptowania na dekady.
- Struktury sterujące: Wprowadził pętle
for,whileoraz instrukcjeif-then-else, czyniąc skrypty Turing-kompletnymi. - Automatyzacja bootowania: To w Bourne Shell pisano tzw. init skrypty, które konfigurowały system przy starcie (np. montowanie dysków, start sieci).
- Zmienne i środowisko: Możliwość przekazywania parametrów i zmiennych środowiskowych między procesami.
Większość dzisiejszych skryptów .sh (bash) zachowuje kompatybilność z tym standardem sprzed 45 lat.
for file in *.jpg; do
mv "$file" "image_${file}"
done
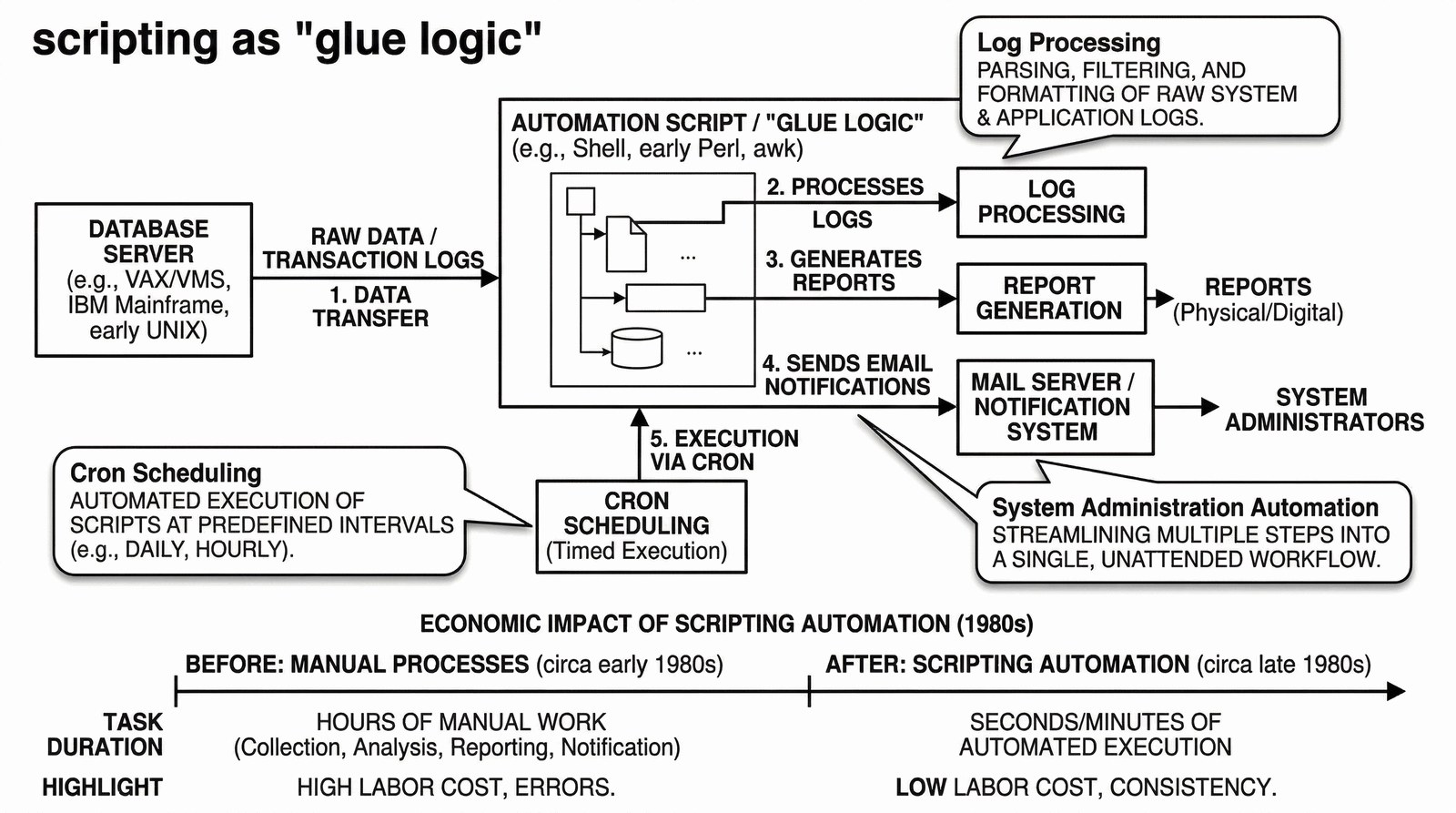
Integracja różnych technologii
W latach 80. skryptowanie zaczęło pełnić rolę "kleju" (glue logic), łącząc niekompatybilne aplikacje w spójne workflow.
- Przetwarzanie logów: Automatyczne wyciąganie błędów z plików tekstowych i wysyłanie powiadomień.
- Harmonogramowanie: Wykorzystanie demona
crondo uruchamiania skryptów o określonych porach (np. backup o 3:00 rano). - Administracja: Zamiast ręcznej konfiguracji 100 kont użytkowników, pisano skrypt, który robił to w sekundę.
Bez skryptów "klejących" zarządzanie dużymi systemami byłoby ekonomicznie niemożliwe.
[DB] -> [Script] -> [Report]
^ | ^
|______( glue )____|
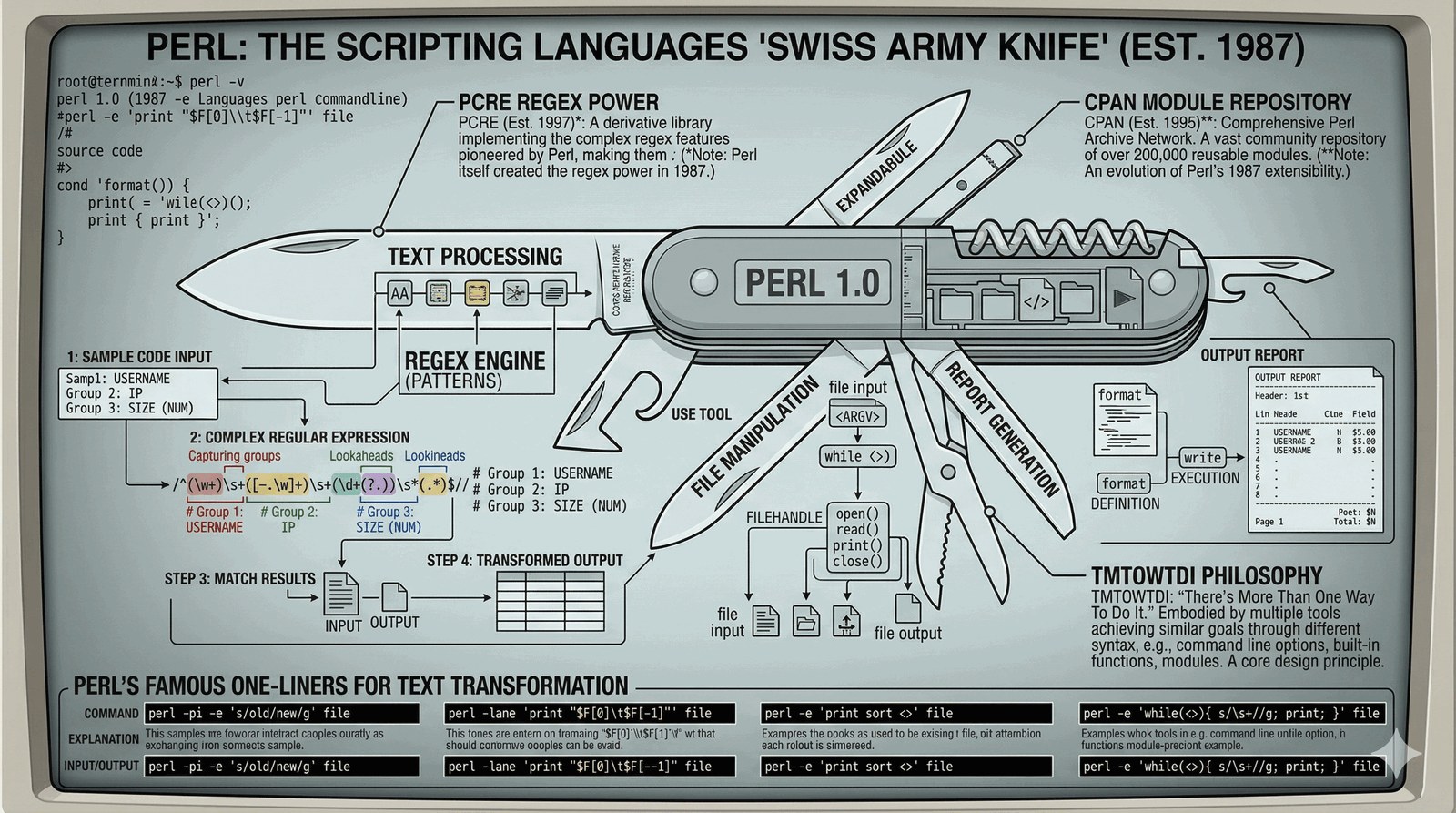
Era potężnego przetwarzania tekstu
Larry Wall (lingwista i programista) stworzył Perla, aby połączyć moc C z prostotą sh. Perl stał się "Szwajcarskim Scyzorykiem" administratorów.
- Wyrażenia regularne (Regex): Perl wprowadził niespotykaną wcześniej moc wyszukiwania i manipulacji tekstem, która do dziś jest wzorcem dla innych języków (PCRE).
- CPAN: Pierwsze ogromne repozytorium gotowych modułów. Programista nie musiał pisać wszystkiego od zera - mógł pobrać bibliotekę do wszystkiego.
- TMTOWTDI: "There's More Than One Way To Do It" - filozofia dająca programiście wolność wyboru stylu.
while (<>) {
s/apple/orange/g;
print;
}
# Legendarne regexy!
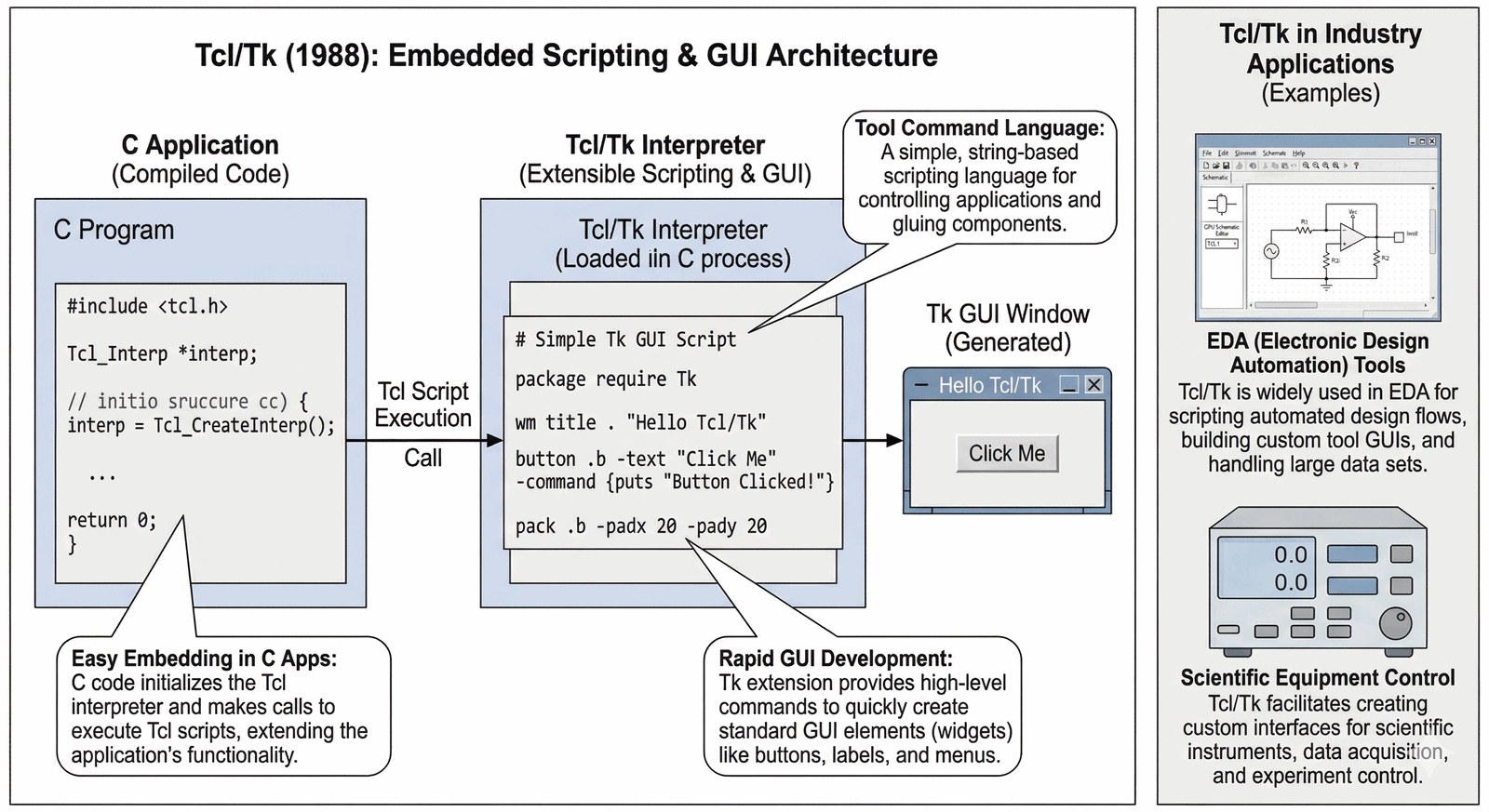
Skryptowanie wbudowane i GUI
John Ousterhout stworzył Tcl jako język, który można łatwo osadzić (embed) wewnątrz dużych aplikacji napisanych w C.
- Rozszerzalność: Programista pisał rdzeń aplikacji w C dla wydajności, a logikę sterującą w Tcl dla wygody.
- Biblioteka Tk: Pozwoliła na tworzenie okienkowych interfejsów (GUI) za pomocą kilku linii skryptu. To był szok dla ludzi piszących tysiące linii kodu w Xlib.
- Używany do dziś w narzędziach do projektowania procesorów (EDA) i sterowania aparaturą naukową.
button .b -text "Hello" \
-command {exit}
pack .b
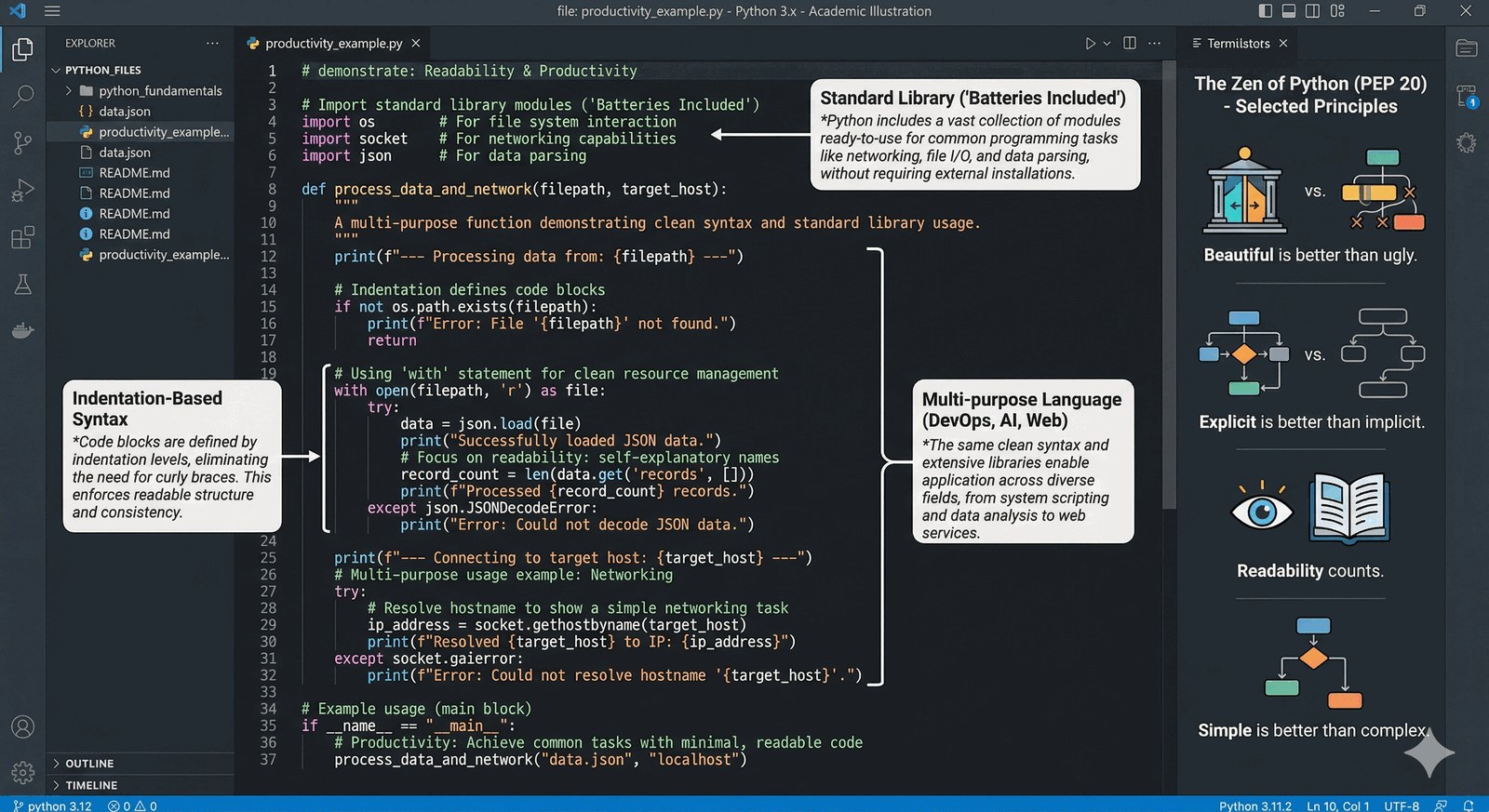
Skryptowanie jako inżynieria
Guido van Rossum stworzył Pythona, aby rozwiązać problem "nieczytelnych skryptów" w Perlu. Skupił się na czytelności i produktywności.
- Wcięcie ma znaczenie: Struktura kodu jest wymuszona przez spacje, co sprawia, że kod wszystkich programistów wygląda podobnie i jest łatwy do czytania.
- Batteries Included: Ogromna biblioteka standardowa pozwalająca na pracę z siecią, plikami i danymi "prosto z pudełka".
- Uniwersalność: Python przestał być tylko "skryptem" - stał się pełnoprawnym językiem do budowy backendu, AI i systemów rozproszonych.
import this
# Zen of Python:
# Beautiful is better
# than ugly.
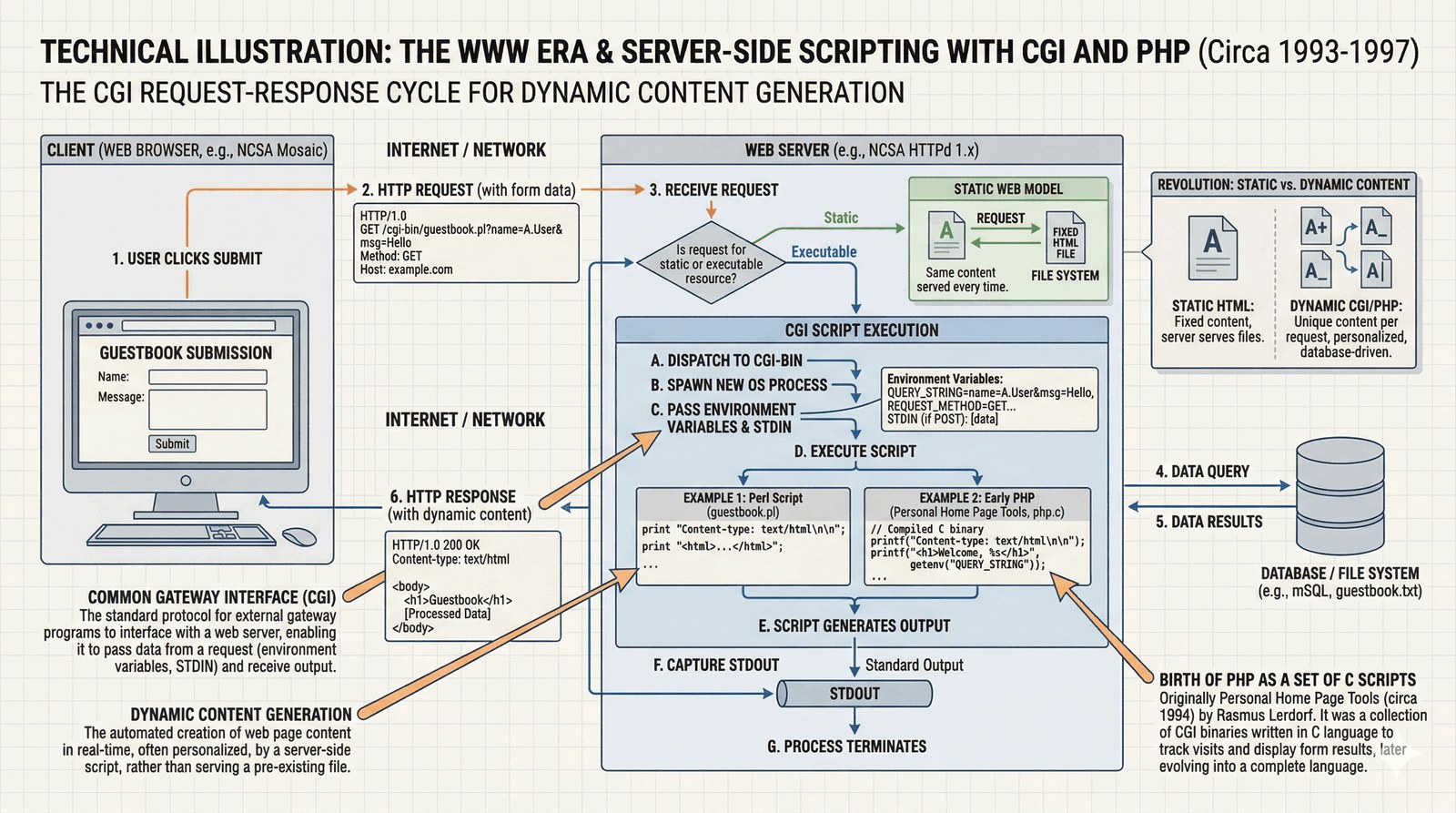
Skrypt na serwerze
W latach 90. skryptowanie zasiliło rewolucję internetową poprzez standard CGI (Common Gateway Interface).
- Dynamiczne treści: Serwer WWW, zamiast wysyłać statyczny plik HTML, uruchamiał skrypt (często w Perlu), który generował HTML na bieżąco (np. z wynikami wyszukiwania).
- Narodziny PHP: PHP powstał jako zestaw skryptów C w celu monitorowania stron domowych. Szybko stał się najpopularniejszym językiem webowym dzięki wbudowaniu bezpośrednio w HTML.
- Wyzwanie wydajności: Każde żądanie HTTP uruchamiało nowy proces (fork), co wymusiło powstanie technologii takich jak FastCGI i serwery aplikacyjne.
<?php
echo "Witaj, świecie!";
?>
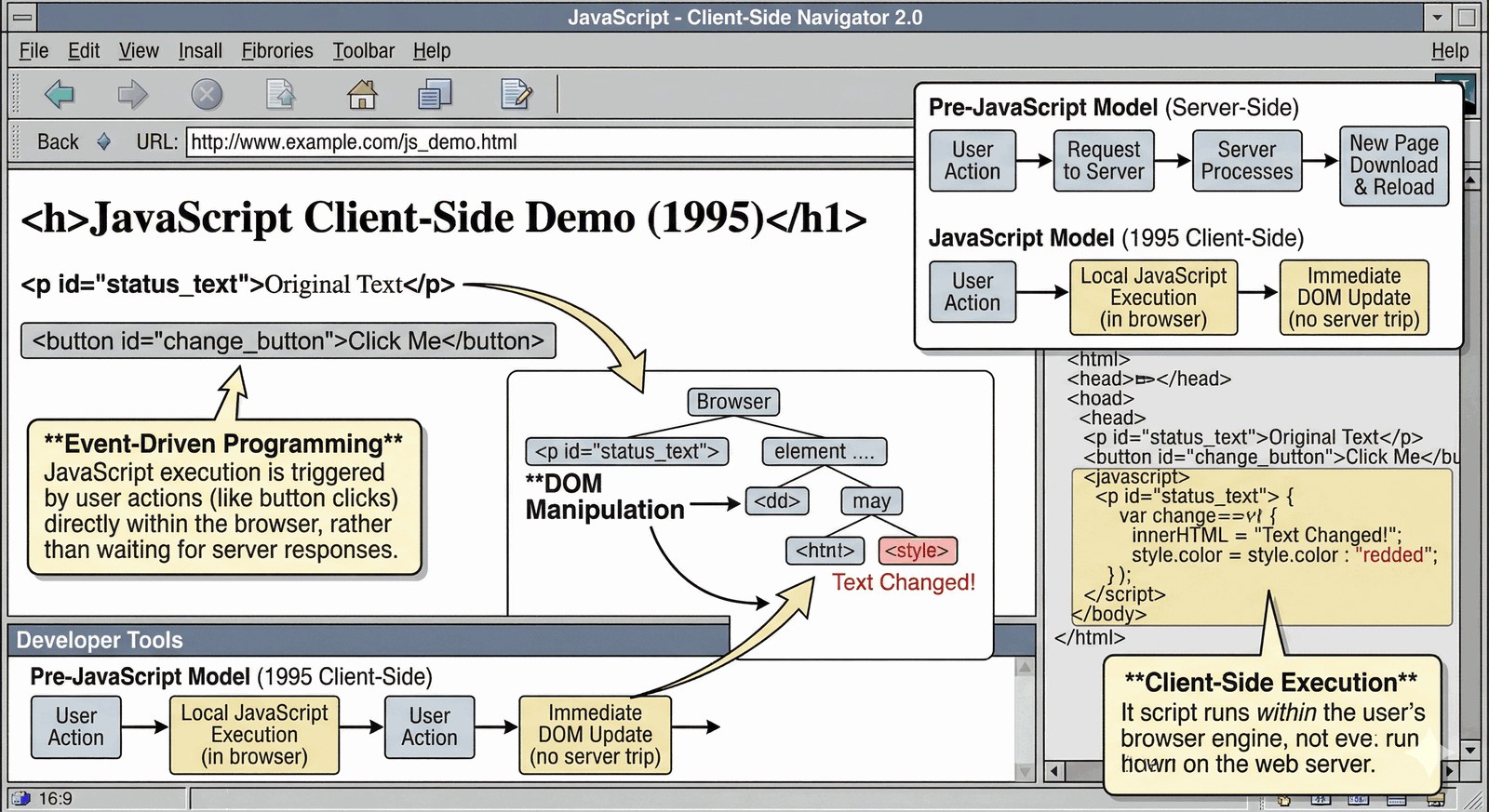
Skryptowanie po stronie klienta
JavaScript (stworzony przez Brendana Eicha w 10 dni) umożliwił uruchamianie kodu bezpośrednio w przeglądarce użytkownika.
- Manipulacja DOM: Skrypt mógł zmieniać treść, kolory i zachowanie strony bez przeładowywania jej z serwera.
- Programowanie zdarzeniowe: Kod reaguje na kliknięcia, ruchy myszy i wpisywanie tekstu przez użytkownika.
- Udostępnienie mocy: JavaScript przekazał część pracy obliczeniowej z serwera na komputer użytkownika, co pozwoliło na budowę bogatych aplikacji webowych.
alert("Hello World!");
document.getElementById("hello")
Skryptowanie na sterydach
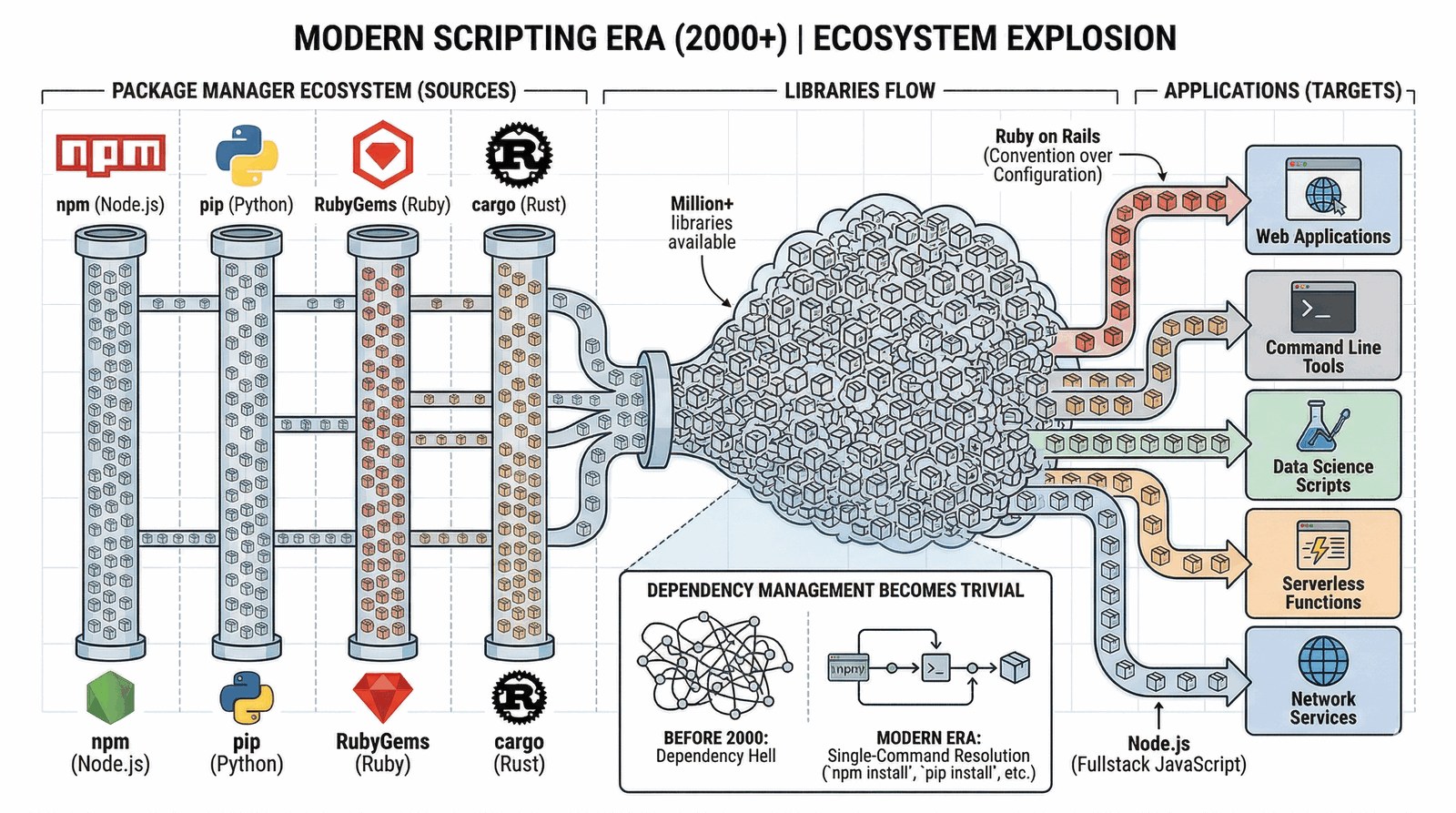
Po roku 2000 języki skryptowe zaczęły dominować w niemal każdej dziedzinie IT.
- Ruby on Rails (2004): Wprowadził koncepcję "Convention over Configuration", pozwalając na budowę startupów w kilka tygodni, a nie miesięcy.
- Rozwój NPM i PyPI: Zarządzanie tysiącami zależności stało się banalne, co doprowadziło do powstania ekosystemów liczących miliony bibliotek.
- Node.js: Przeniesienie JavaScriptu z powrotem na serwer, co zatarło różnice między frontendem a backendem (Fullstack).
Skryptowanie stało się domyślnym sposobem budowania logiki biznesowej aplikacji.
[Package Managers]
pip, npm, gem, cargo
Cały świat w zasięgu
jednej komendy.
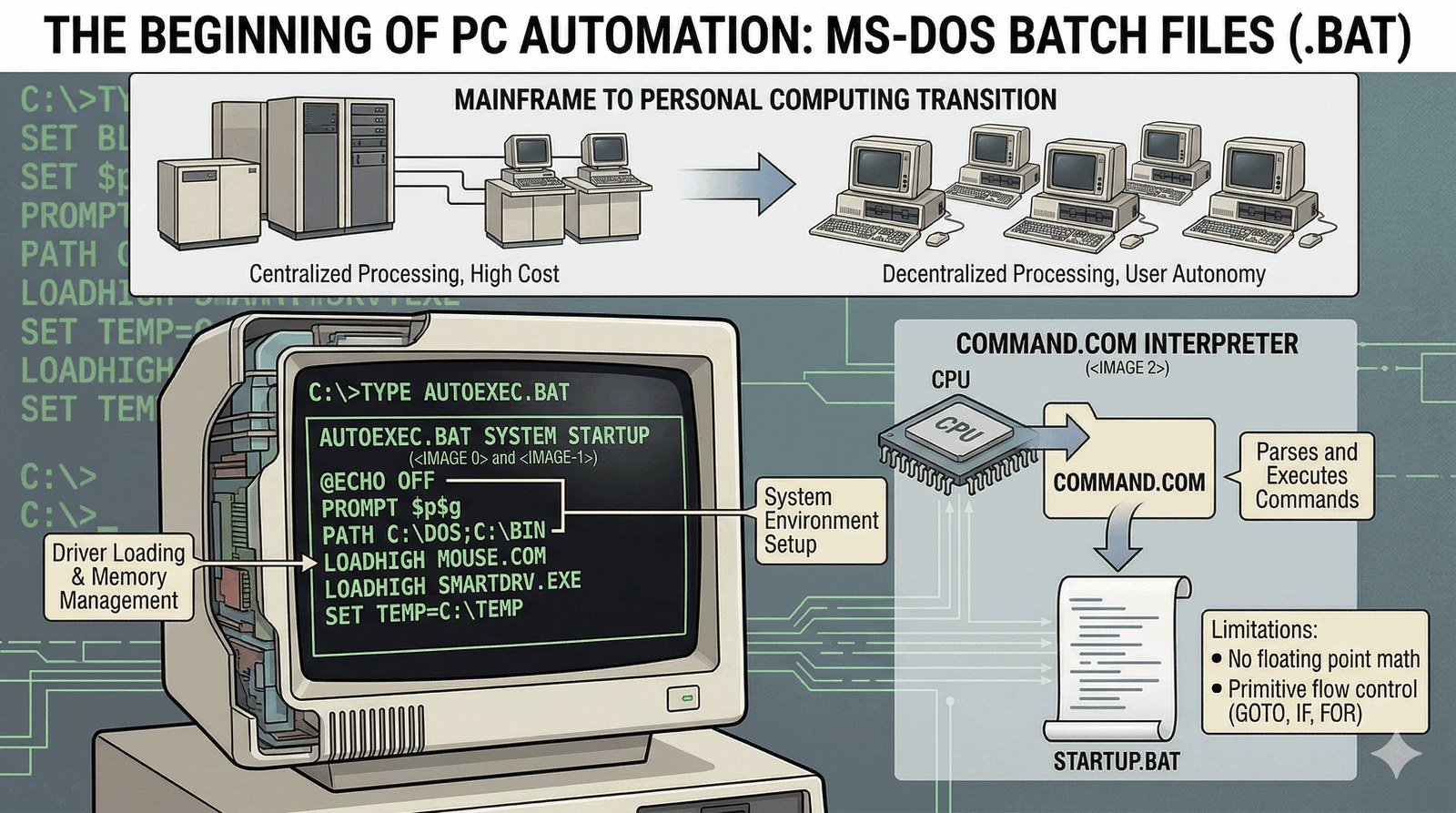
Pliki .bat (MS-DOS)
W świecie PC skryptowanie zaczęło się od plików wsadowych .bat. To one pozwoliły użytkownikom domowym na pierwsze kroki w automatyzacji.
- COMMAND.COM: Interpreter, który wczytywał każdą linię skryptu po kolei.
- Automatyzacja startu: Plik
AUTOEXEC.BATbył kluczowy - to w nim ładowano sterowniki myszy, karty dźwiękowej i zarządzano ograniczoną pamięcią RAM (640KB!). - Ograniczenia: Brak zaawansowanych funkcji (np. operacji zmiennoprzecinkowych) i trudna składnia pętli.
@echo off
echo Loading drivers...
C:\DOS\SMARTDRV.EXE
PROMPT $P$G
WSH, VBScript i JScript
Wraz z nadejściem Windows 98/NT, Microsoft wprowadził potężniejsze narzędzia oparte na architekturze COM (Component Object Model).
- VBScript: Pozwolił na automatyzację zadań administracyjnych (np. tworzenie kont w Active Directory) za pomocą obiektów.
- Zagrożenia: Moc WSH została wykorzystana przez twórców wirusów (np. I Love You), co pokazało, jak niebezpieczne może być skryptowanie bez odpowiednich zabezpieczeń.
- Integracja: Skrypty mogły kontrolować aplikacje Office (Excel, Word) poprzez mechanizm automatyzacji.
WSH był solidnym mostem między prostym DOS-em a nowoczesnym PowerShell-em.
Set objFSO = CreateObject(...)
objFSO.CreateTextFile("log.txt")
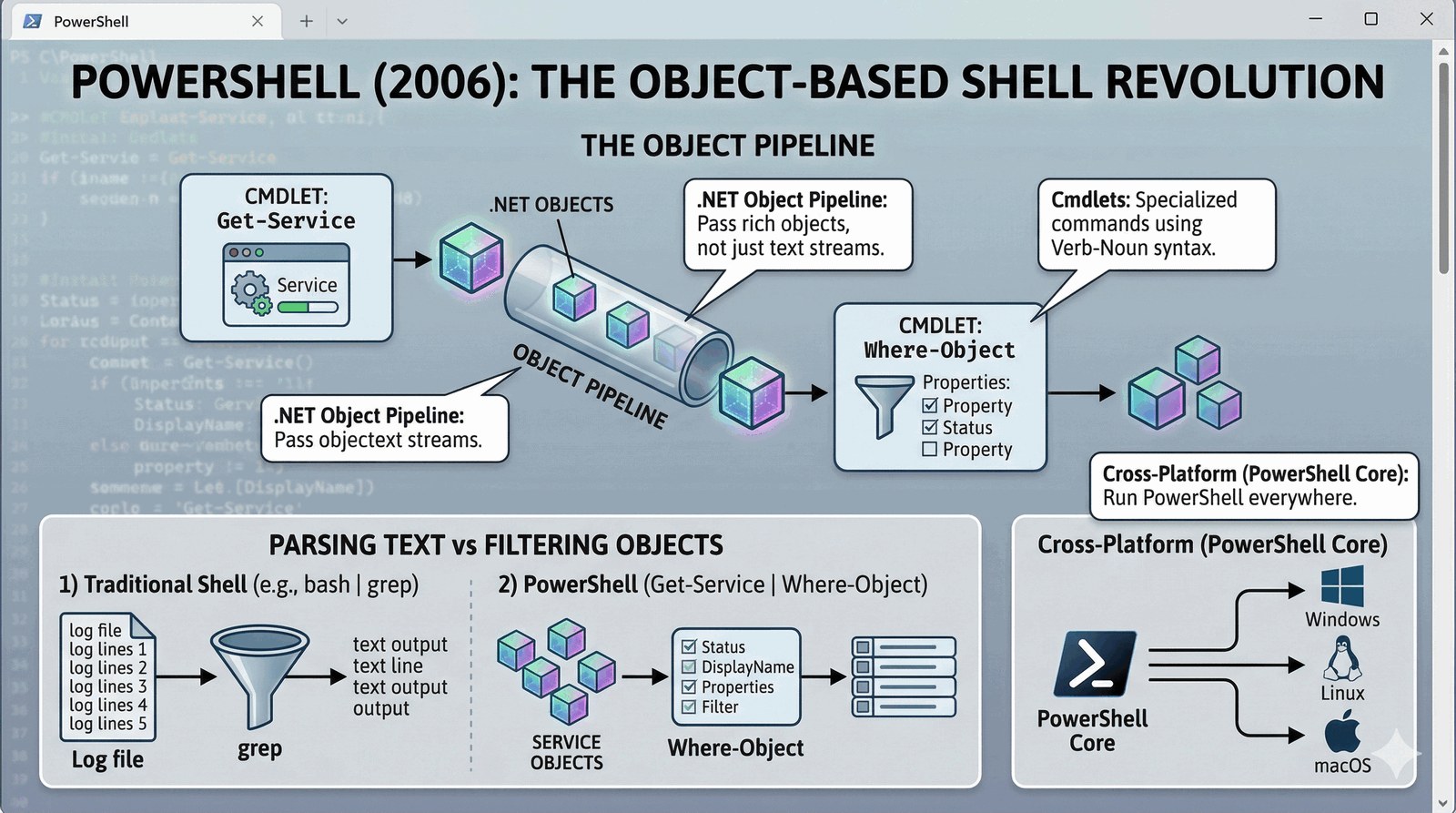
Obiekty zamiast tekstu
PowerShell (stworzony przez Jeffreya Snovera w 2006) to rewolucja w podejściu do powłoki. Zamiast operować na strumieniach tekstu, PS operuje na obiektach .NET.
- Verb-Noun syntax: Przejrzysta struktura komend (np.
Get-Service,Stop-Process) ułatwia naukę i przewidywanie nazw poleceń. - Pipeline: Przesyła całe obiekty z ich właściwościami i metodami, co eliminuje potrzebę skomplikowanego parsowania tekstu przez Regex.
- Uniwersalność: Dzięki PowerShell Core (2016) stał się narzędziem wieloplatformowym (Windows, Linux, macOS) i standardem w chmurze Azure.
Get-Service |
Where-Object {$_.Status -eq "Stopped"}
# Obiektowa magia!
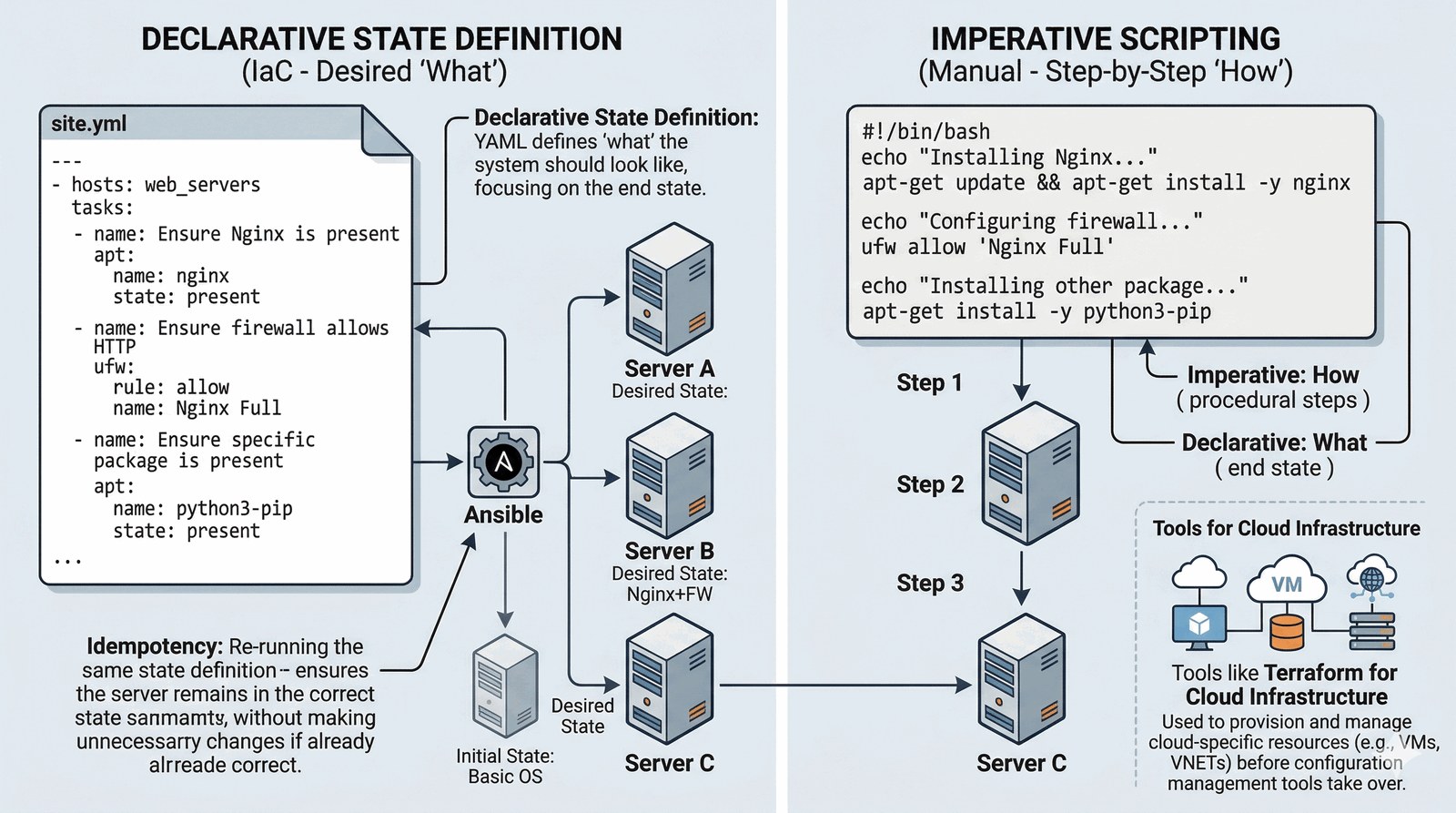
Skryptowanie jako definicja stanu
Nowoczesne skryptowanie ewoluowało w stronę deklaratywności. Zamiast pisać "jak" coś zrobić, piszemy "co" ma być efektem końcowym.
- Ansible & YAML: Skrypty definiujące konfigurację serwerów ("Chcę, aby Apache był zainstalowany"). System sam sprawdza różnicę między stanem obecnym a docelowym.
- Terraform: Zarządzanie fizyczną infrastrukturą (serwery, sieci, bazy danych) w chmurze za pomocą kodu (HCL).
- Idempotentność: Skrypt można uruchomić wielokrotnie, a system upewni się, że stan docelowy jest zachowany bez duplikowania pracy.
To podstawa dzisiejszej kultury DevOps i automatyzacji w skali chmury.
- name: Install Nginx
apt:
name: nginx
state: present
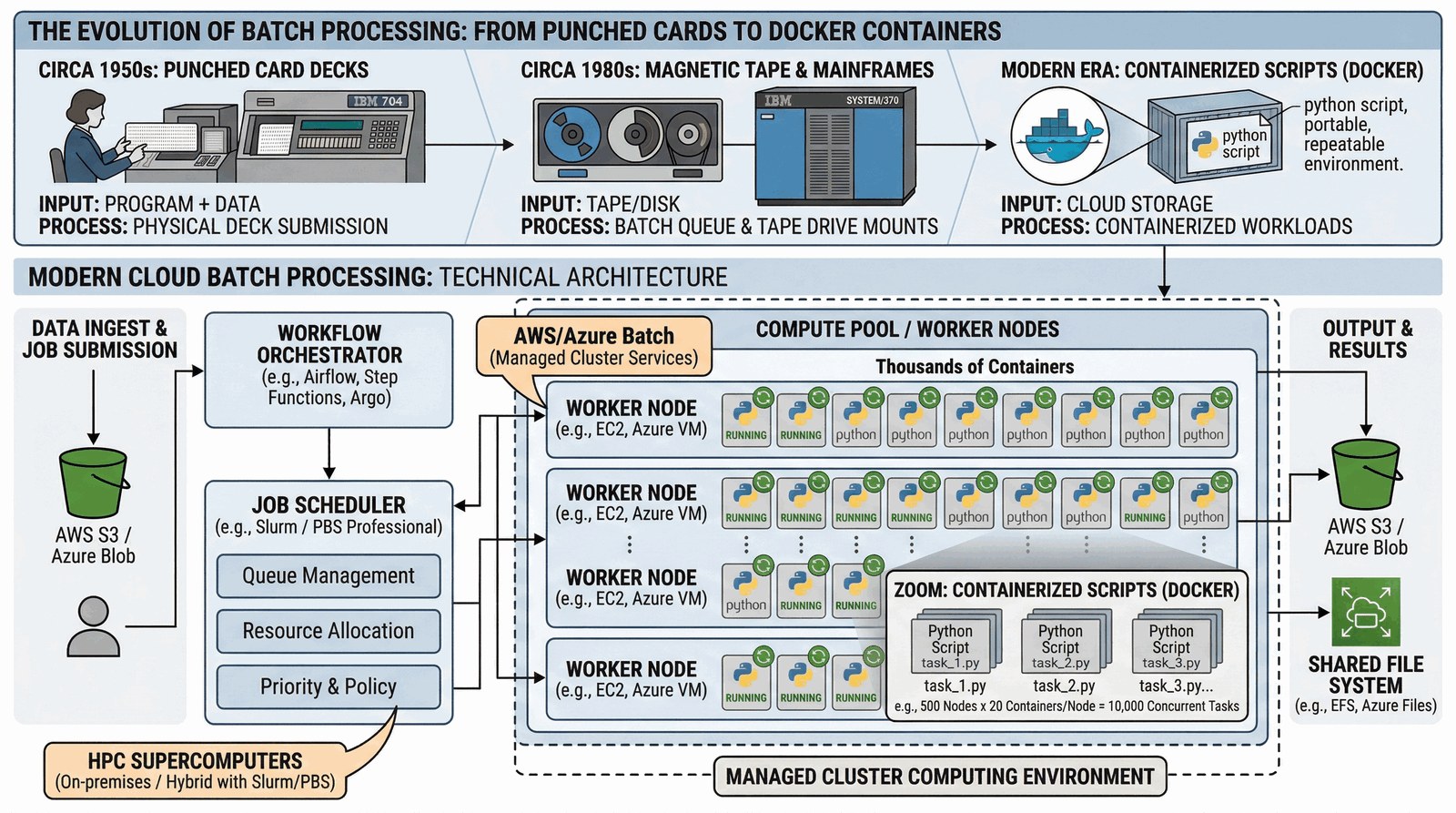
Wsadowość w chmurze
Idea systemów wsadowych powróciła w nowej formie. Dzisiejsze skrypty zarządzają potężnymi klastrami obliczeniowymi.
- AWS Batch / Azure Batch: Automatyczne uruchamianie tysięcy kontenerów z kodem w odpowiedzi na zdarzenia (np. załadowanie nowego filmu do konwersji).
- HPC (High Performance Computing): Skrypty kolejkujące (Slurm / PBS) rozdzielające zadania na tysiące procesorów w superkomputerach.
- Konteneryzacja: Skrypt w Pythonie owinięty w Dockera to dzisiejszy odpowiednik talii kart perforowanych.
#SBATCH --job-name=compute
#SBATCH --nodes=10
srun my_simulation.exe
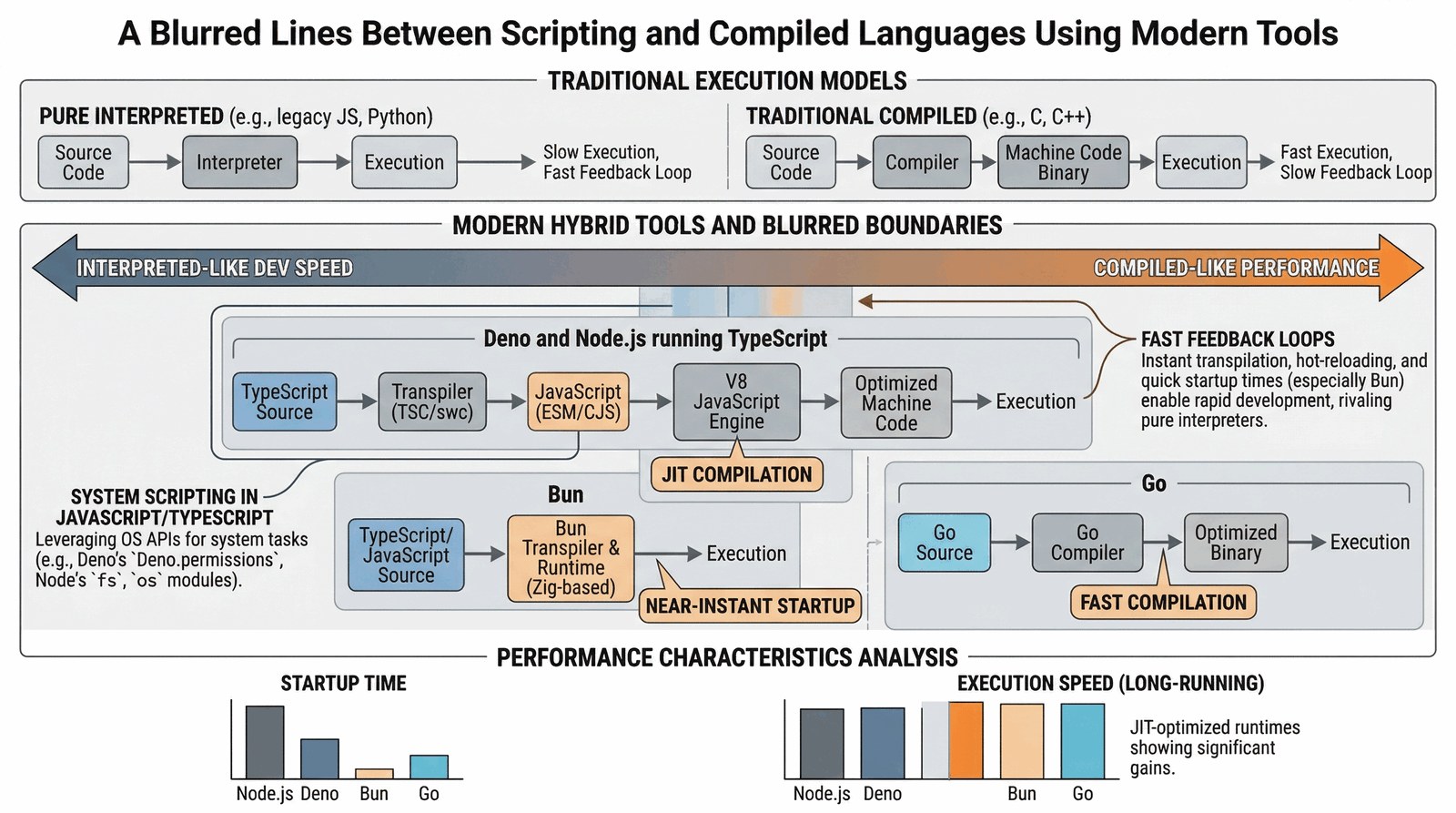
Języki hybrydowe i JIT
Czy Go lub Rust to języki skryptowe? Granice stają się płynne dzięki niespotykanej szybkości kompilacji i technologii JIT.
- Deno/Node.js: Pozwalają na pisanie skryptów systemowych w JavaScript/TypeScript z pełnym dostępem do API systemu operacyjnego.
- Szybka pętla zwrotna: Nowoczesne narzędzia (np. Bun) pozwalają uruchamiać kod niemal natychmiast, co daje wrażenie pracy z interpreterem.
- Wydajność: JIT (Just-In-Time) sprawia, że skrypty w JS czy Pythonie są często wystarczająco szybkie do zadań obliczeniowych.
// Deno: skryptowanie
// w TypeScript
await Deno.writeTextFile("plik.txt", "Hello")
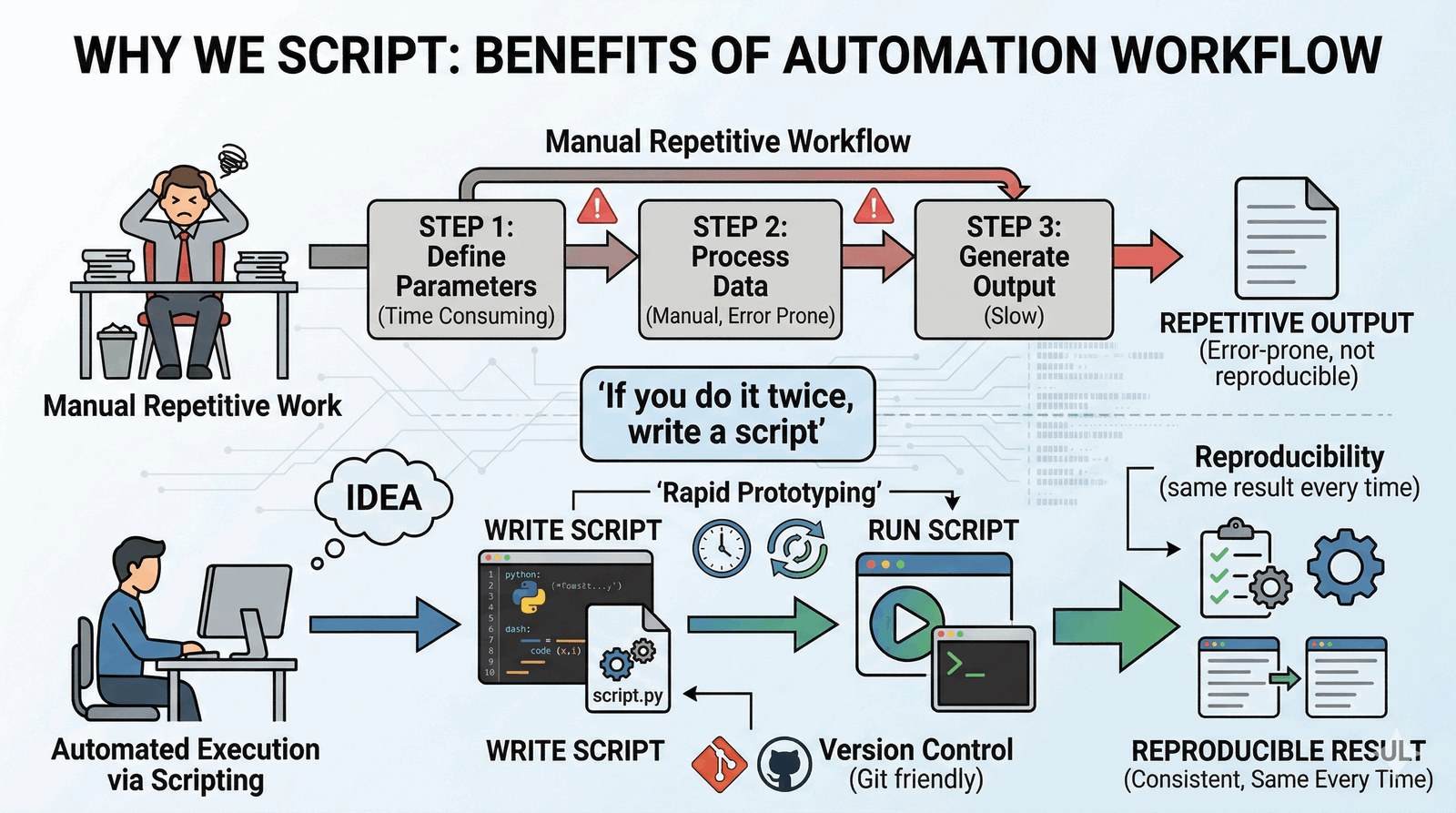
Zalety automatyzacji
Dla inżyniera IT skryptowanie to narzędzie walki ze złożonością i nudą powtarzalnych zadań.
- Szybkość prototypowania: Od pomysłu do działającego narzędzia w kilka minut. "Szybko i dobrze (wystarczająco)".
- Reprodukowalność: Skrypt wykonuje się zawsze tak samo, co eliminuje błędy "zmęczonego operatora".
- Wersjonowanie: Skrypty tekstowe są czytelne i idealnie nadają się do systemów kontroli wersji (Git).
Zasada: Jeśli musisz coś zrobić więcej niż dwa razy - napisz do tego skrypt.
Idea -> Script -> Result
(The shortest path)
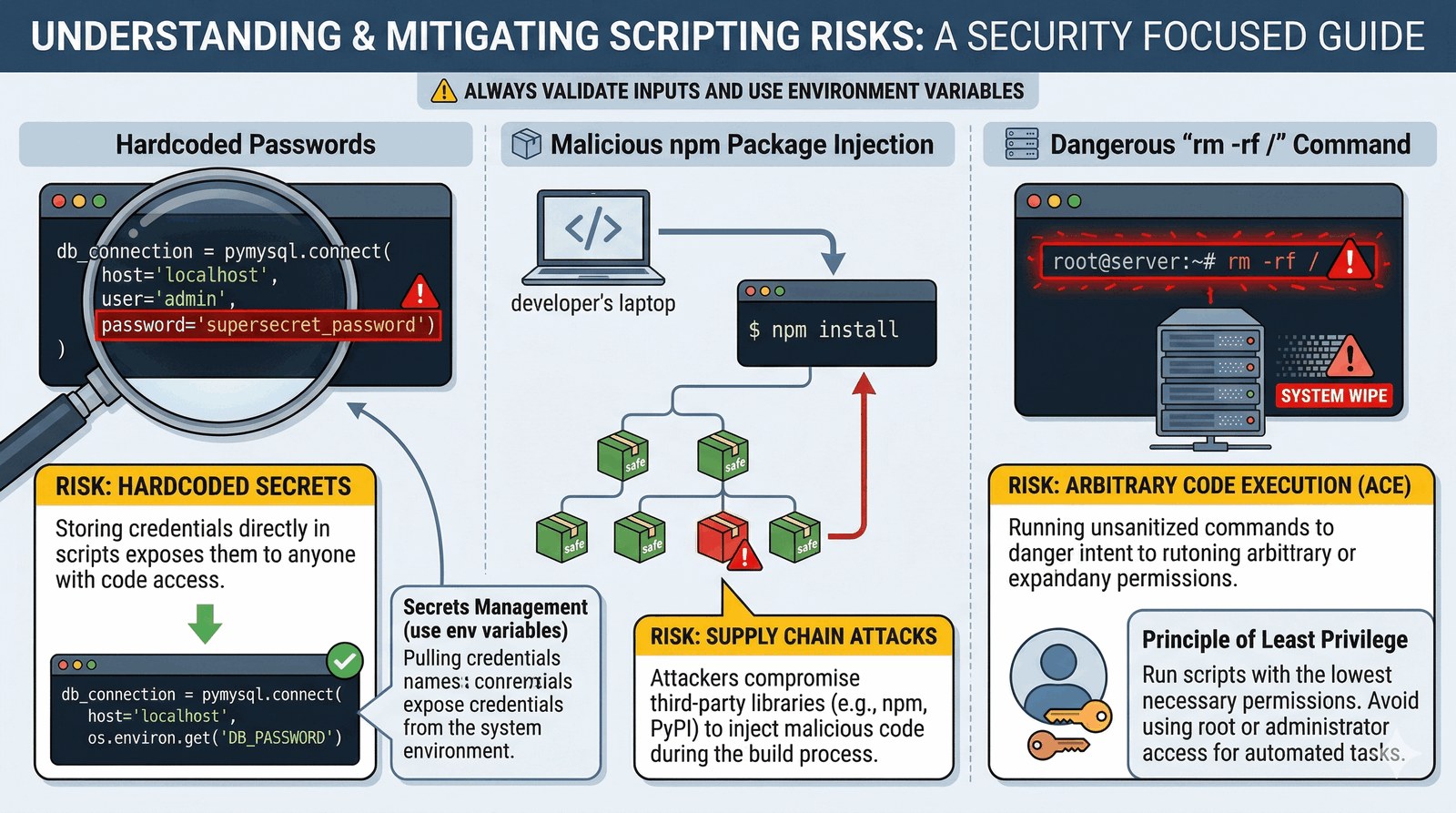
Ciemna strona skryptów
Moc automatyzacji niesie ze sobą ogromną odpowiedzialność. Student IT musi pamiętać o "pułapkach":
- Principle of Least Privilege: Nigdy nie uruchamiaj skryptów jako root/administrator, jeśli nie jest to absolutnie konieczne.
- Supply Chain Attacks: Używanie bibliotek z internetu (np. z NPM) bez weryfikacji może wprowadzić złośliwy kod do Twojego systemu.
- Secrets Management: Nigdy nie wpisuj haseł i kluczy API bezpośrednio w skryptach. Używaj zmiennych środowiskowych lub vaultów.
rm -rf / # Nigdy nie
# puszczaj
# skryptów
# bez nadzoru!
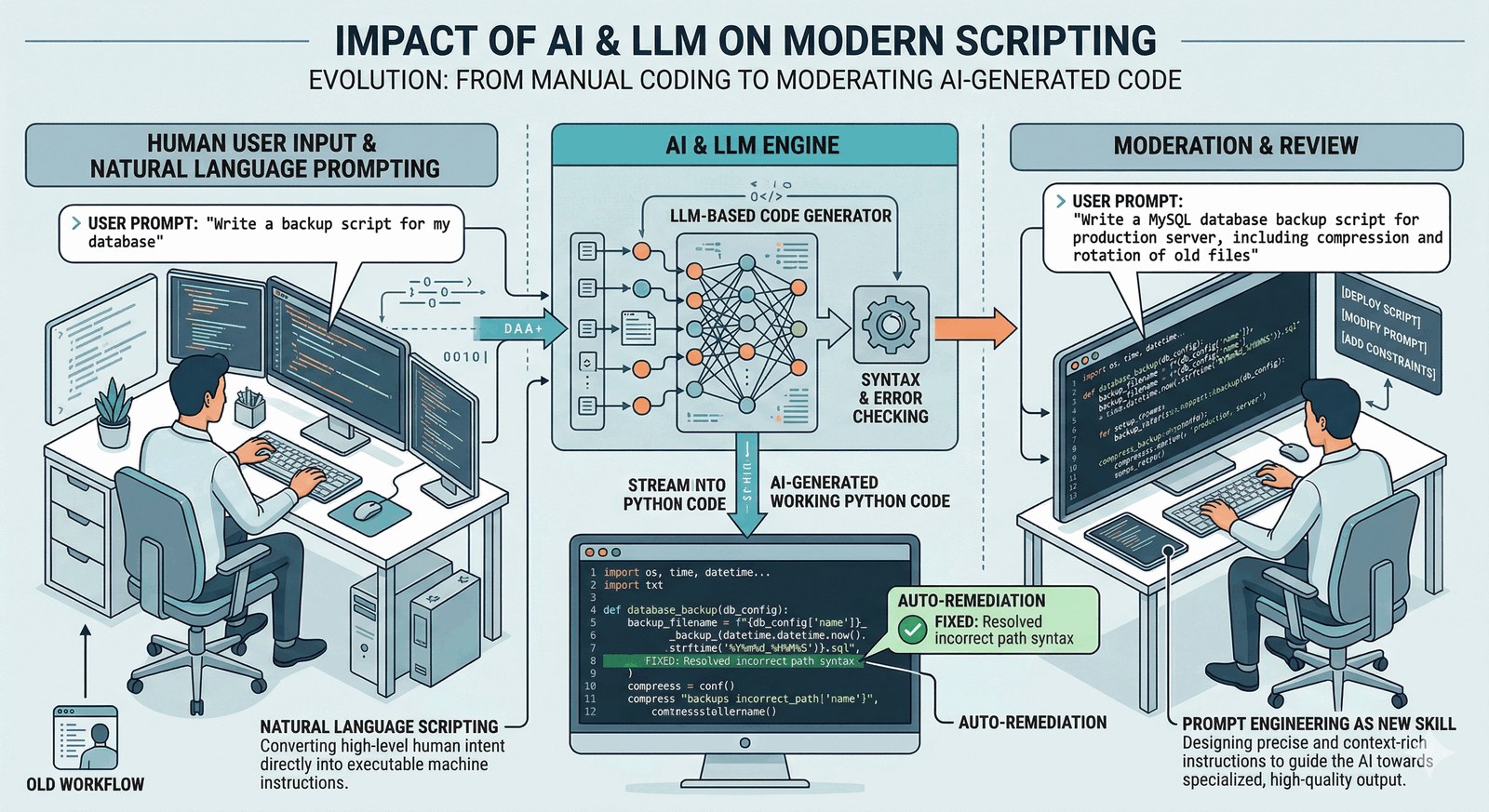
Generowanie automatyczne
Sztuczna Inteligencja (LLM) zmienia paradygmat: programista przestaje pisać kod, a zaczyna go moderować.
- Natural Language Scripting: Modele takie jak GPT-4 czy Claude potrafią pisać bezbłędne (często) skrypty na podstawie opisu słownego.
- Auto-Remediation: Skrypty AI potrafią same wykrywać błędy w logach i sugerować (lub wprowadzać) poprawki w konfiguracji.
- Nowa rola: Umiejętność precyzyjnego opisania problemu (prompt engineering) staje się nowym językiem skryptowym.
User: "Napisz skrypt
do backupu bazy..."
AI: [Generating...]
Przyszłość skryptowania
Od fizycznego łączenia kabli w latach 40. po wirtualne orkiestracje chmurowe - cel pozostał ten sam: abstrakcja nad złożonością sprzętu.
Dla studenta IT skryptowanie to nie tylko dodatkowa umiejętność - to podstawowy oręż w świecie ciągłej integracji i szybkiego dostarczania oprogramowania.
Bibliografia / Źródła:
- "The Art of Unix Programming" - Eric S. Raymond
- Dokumentacja systemów Unix/Linux.
+-------------------+
| KONIEC |
| DZIĘKUJĘ ZA |
| UWAGĘ! |
+-------------------+