Abstrakcja od Sprzętu: Języki Kompilowane
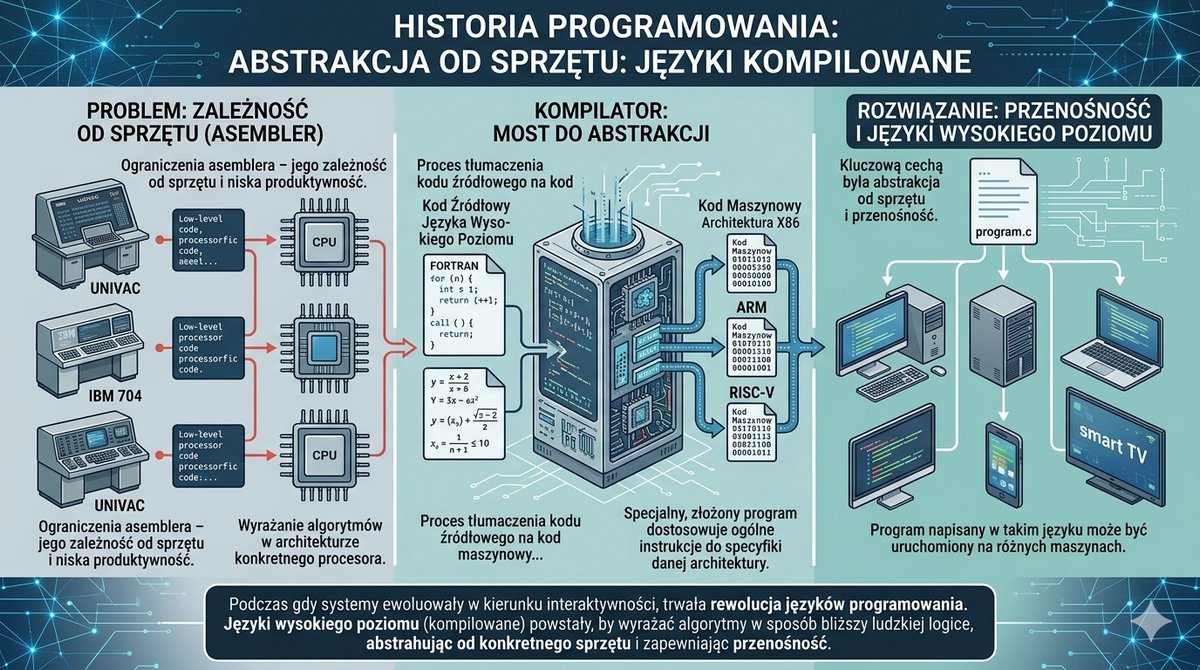
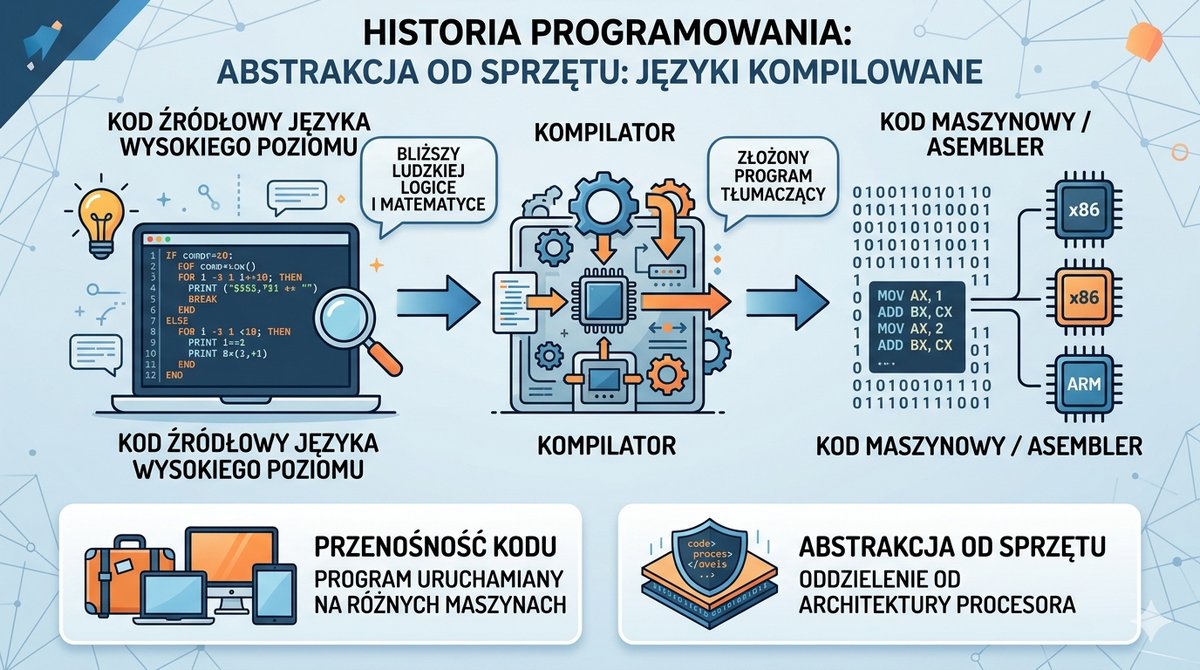
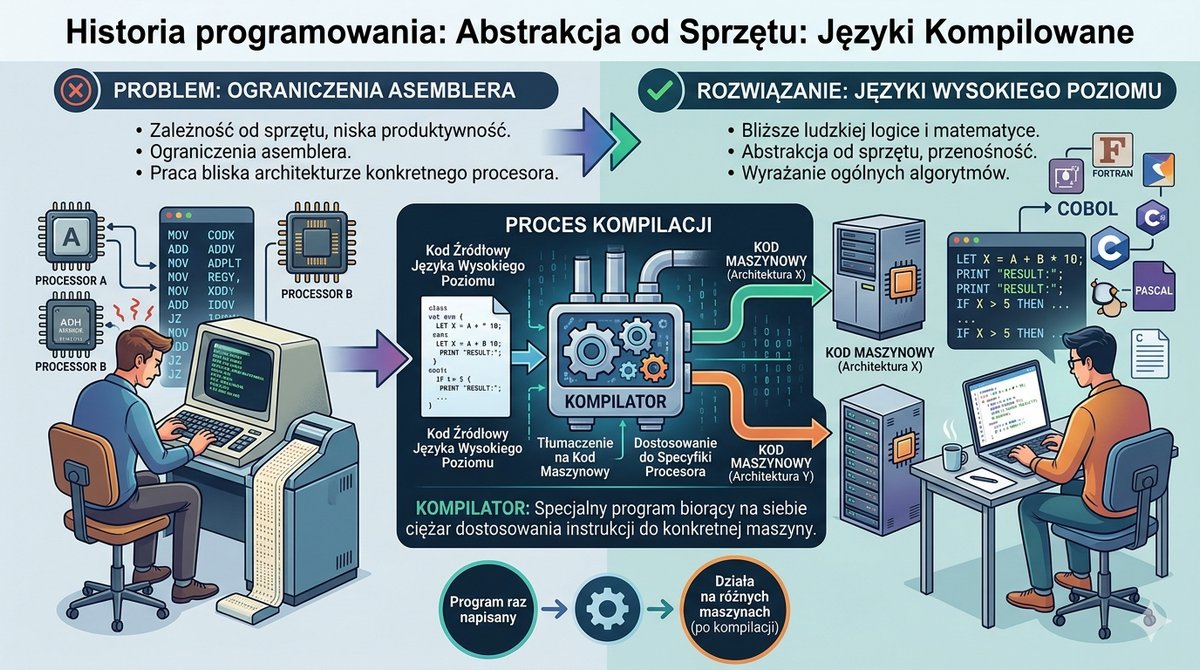
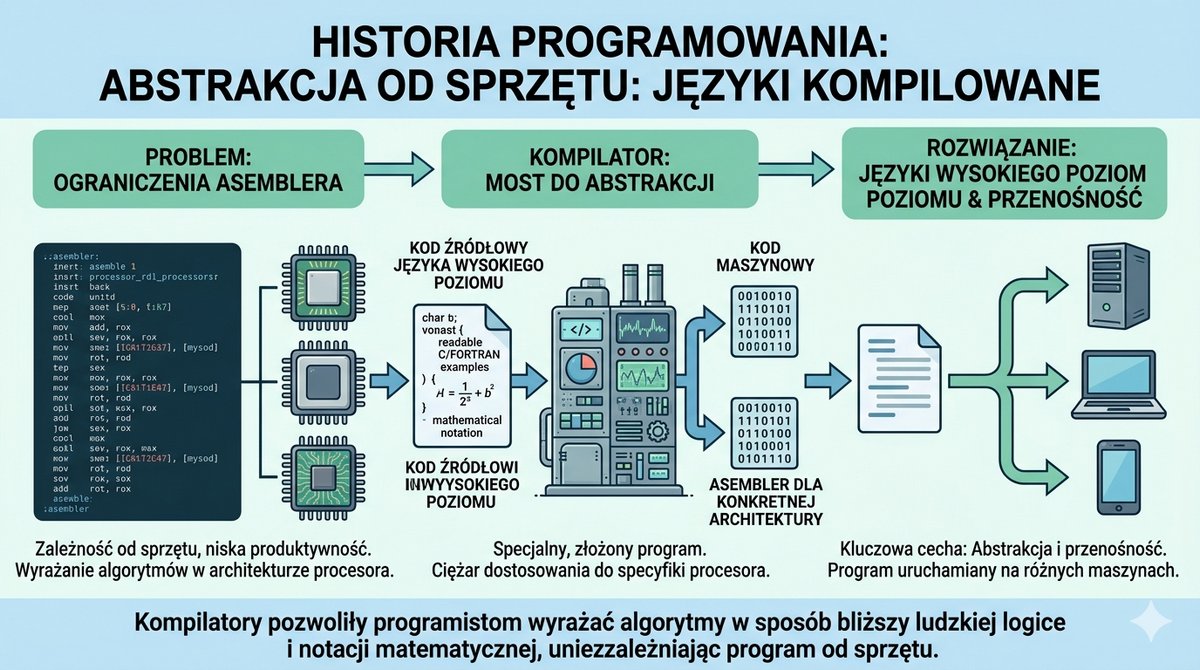
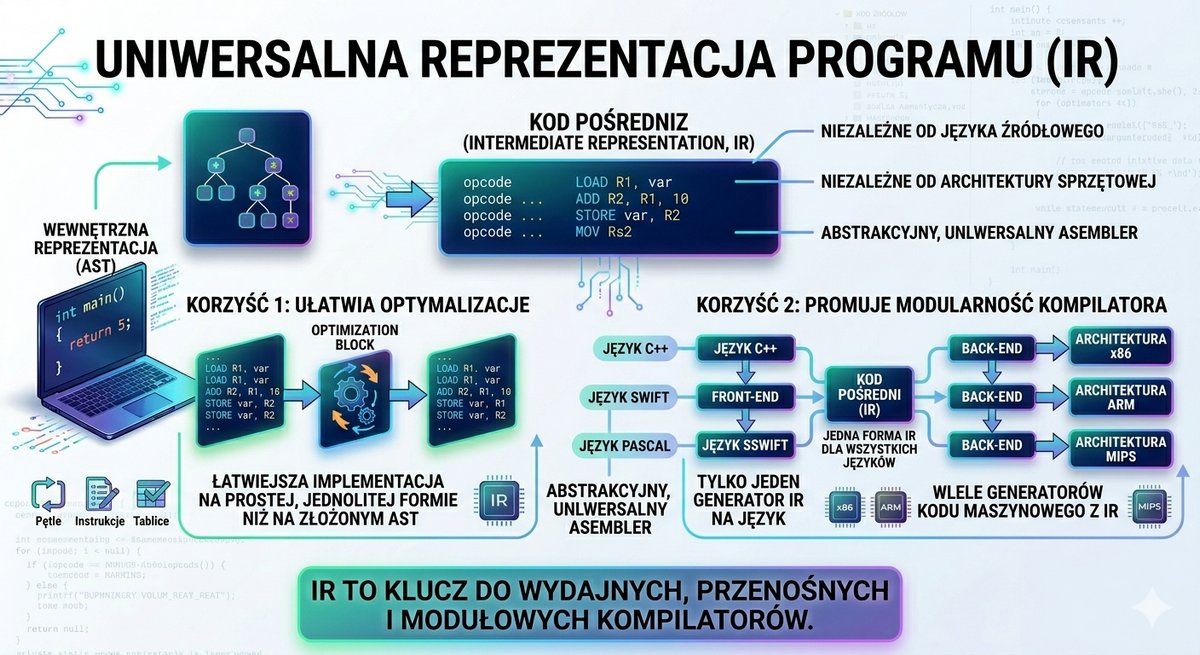
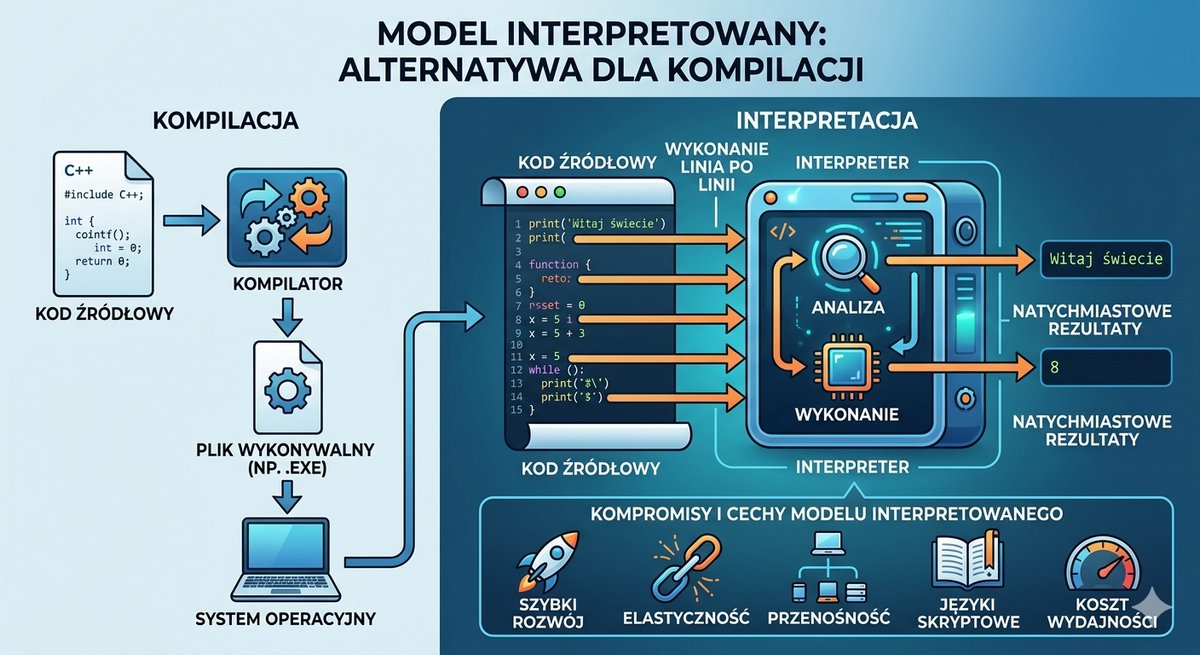
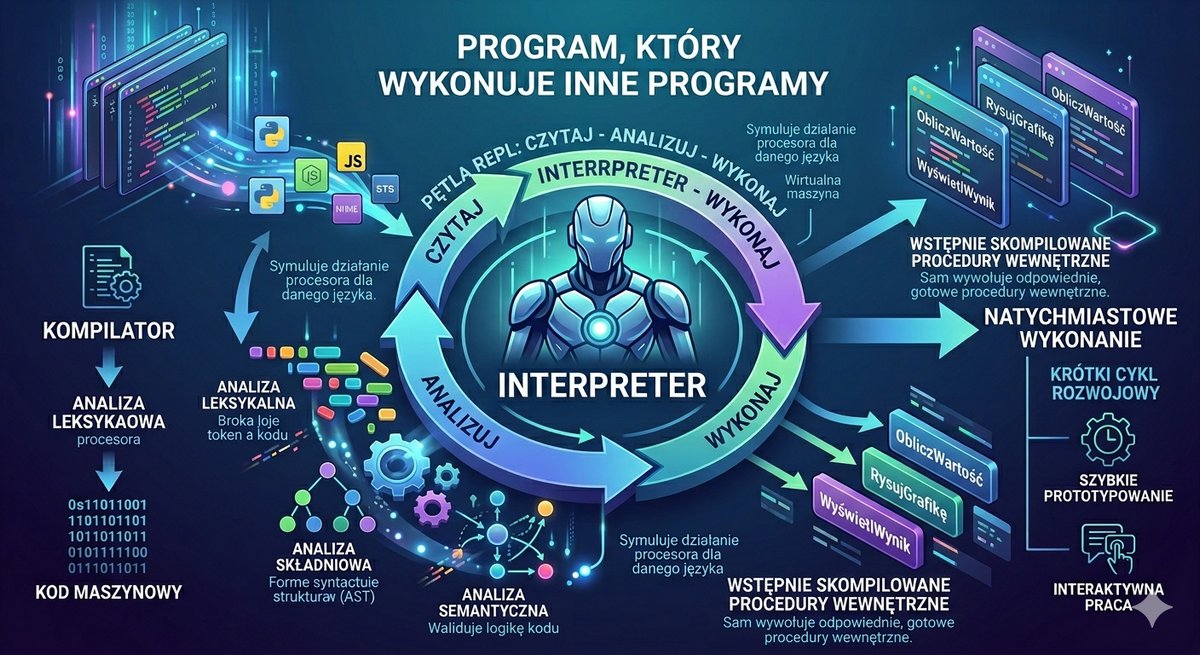
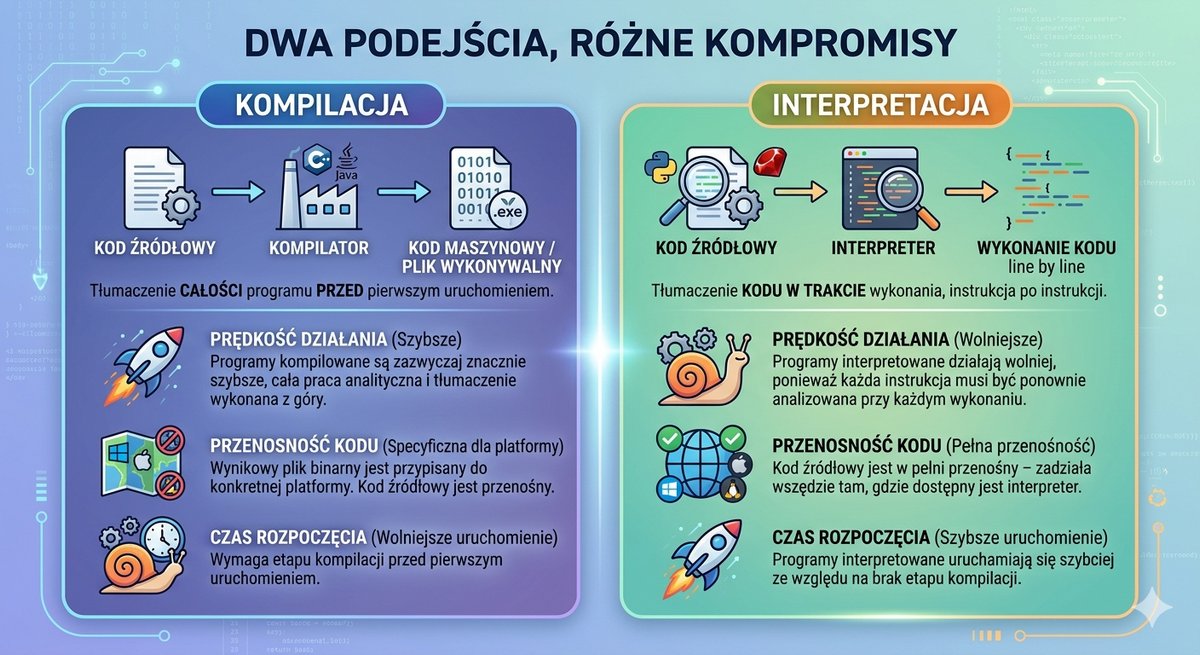
Podczas gdy systemy operacyjne ewoluowały w kierunku interaktywności, równolegle trwała rewolucja w dziedzinie języków programowania. Ograniczenia asemblera – jego zależność od sprzętu i niska produktywność – stawały się coraz bardziej dotkliwe. Zrodziła się potrzeba tworzenia języków, które pozwoliłyby programistom wyrażać algorytmy w sposób bliższy ludzkiej logice i notacji matematycznej, a nie architekturze konkretnego procesora. Tak powstały języki wysokiego poziomu. Ich kluczową cechą była abstrakcja od sprzętu i przenośność. Program napisany w takim języku mógł być, po odpowiednim przetłumaczeniu, uruchomiony na różnych maszynach. Procesem tłumaczenia kodu źródłowego na kod maszynowy zajmował się specjalny, złożony program – kompilator. To on brał na siebie ciężar dostosowania ogólnych instrukcji do specyfiki danej architektury procesora.